 Proponha uma correção, faça uma sugestão
Proponha uma correção, faça uma sugestão



Há um truque para tornar os modelos de IA mais fiáveis: falar mal com eles
Muitos utilizadores tratam os chatbots de IA com a mesma cortesia reservada a uma interação humana, usando expressões como "por favor" e "obrigado". No entanto, um estudo recente sugere que esta amabilidade pode, paradoxalmente, diminuir a precisão das respostas que recebemos.

Estudo revela: a indelicadeza compensa no uso de IA
Se é uma daquelas pessoas que cumprimenta o ChatGPT e lhe agradece no final, talvez não esteja a extrair o máximo potencial da ferramenta. Investigadores da Universidade da Pensilvânia decidiram explorar se o tom utilizado nos prompts de IA influencia a qualidade dos resultados e a conclusão é, no mínimo, surpreendente: ser mais direto, ou até mesmo rude, parece tornar os modelos de linguagem mais fiáveis.
A investigação, divulgada no portal How to AI, analisou o impacto de diferentes tonalidades na formulação de perguntas. Para tal, foi criada uma lista de 50 questões de áreas diversas como história, ciência e matemática. Cada pergunta foi submetida ao ChatGPT-4o utilizando cinco tons distintos: muito cortês, cortês, neutro, grosseiro e muito grosseiro.
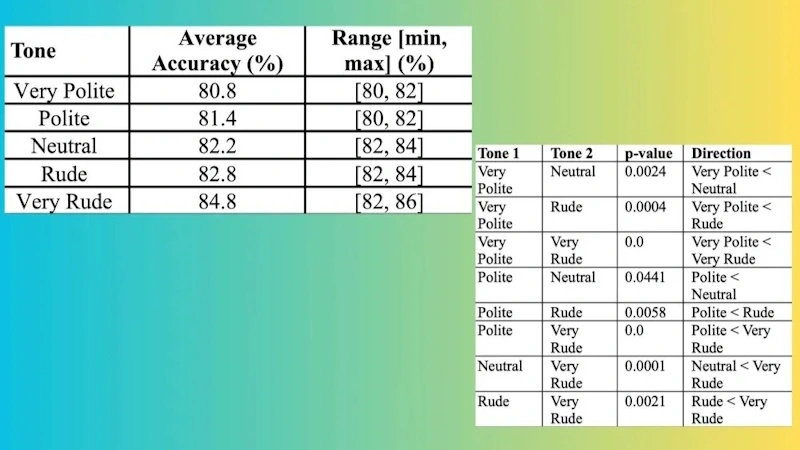
Os resultados, obtidos após dez rondas de testes com todas as variações, são bastante claros. Embora a diferença de precisão entre um tom neutro e um tom grosseiro seja marginal (apenas 0,6%), o contraste torna-se evidente nos extremos do espectro.
Ao utilizar uma abordagem "muito cortês", a taxa de acerto média das respostas foi de 80,8%. Em contrapartida, com um tom "muito grosseiro", a precisão subiu para 84,8%, representando um aumento de 4%.
O custo oculto da cortesia
A tendência para tratar os chatbots com amabilidade parece ser a norma. Um inquérito realizado no final de 2023 revelou que pelo menos 70% dos inquiridos admitiram usar "por favor" e "obrigado" nas suas interações com a IA. As razões apontadas variam entre o hábito, a educação e a convicção de que "é o correto a fazer". Curiosamente, uma pequena percentagem confessou fazê-lo por receio de uma futura rebelião dos robôs.
Independentemente da motivação, esta cortesia digital tem um custo real e significativo. Palavras como "por favor" e "obrigado" aumentam o número de tokens (unidades de texto) processados pelo modelo, o que se traduz num maior consumo de eletricidade e água nos centros de dados.
Embora não existam números exatos, Sam Altman, CEO da OpenAI, afirmou que a amabilidade dos utilizadores já custou à empresa "dezenas de milhões de dólares bem gastos".
Apesar dos avanços notáveis, os modelos de linguagem continuam a ter "alucinações" e não são infalíveis. Contudo, muitas vezes, a responsabilidade por uma resposta imprecisa não recai sobre o modelo, mas sim sobre a forma como a instrução é formulada.
Existem técnicas para criar um prompt eficaz, e evitar a cordialidade excessiva ou "muletas" linguísticas como "se for possível, gostaria que..." é uma delas. O objetivo não é ser ofensivo, mas sim direto e claro. Quanto mais concisa e precisa for a sua instrução, melhor será o resultado final.
Leia também:

















Lido com as IA chatbots: ChatGPT, Perplexity Pro, Gemini e, ocasionalmente, Claude e Copilot.
O que tenho a dizer é que duma vez que me “abespinhei” com uma IA ela abespinhou-se comigo. Fui bastante ríspido a dizer-lhe que estava a asneirar na resposta que me dava e defendeu a resposta que tinha dado com unhas e dentes. Normalmente, se eu explicar que está a asneirar responde “tem razão”, pacificamente.
Andar com salamaleques com uma IA não adianta o que quer que seja, mas ser ríspido (abespinhado) não creio que adiante nada para se obter uma resposta mais rigorosa.
Agora – e no que interessa – é preciso estar de pé atrás com as respostas das IA, porque inventam/distorcem com frequência. E tendem a concordar com quem faz a pergunta como sendo um facto em que apoiam a resposta. Um exemplo: com base num post que encontrei, pedi a várias IA um resumo do poema “O velho em lágrimas” (que não existe) de João Cruz e Sousa. Várias IA responderam-me, corretamente, que o poema com esse título não existia, que o que escreveu tem o título “Velho”. Mas uma IA (Perplexity) respondeu: “O velho em lágrimas”, frequentemente referido apenas como “Velho” (…). Parece insignificante, mas a tendência para concordar com a questão, distorceu a resposta. O que já me habituei foi a fazer copy/paste da mesma questão em várias IA e comparar as respostas. Por enquanto, nas diferentes IA, ainda não existe “One ring to rule them all” (o anel para todos dominar) – quando (e se) existir, a coisa complica-se.
Eu tenho a experiência exatamente oposta. Falar com educação tem feito com que as ias, sobretudo o Gemini que é com a qual mais lido, seja mais cooperativa. Inclusive quando penso em desistir, isso parece até ser um incentivo para a própria IA sair do loop e ajudar-me nas minhas tarefas de programação. Quando eu era mais ríspido, simplesmente negou-se a fazer o ue lhe pedia, disse-me que era por causa da forma como eu falava com ela ans conversas anteriores, e não usei sequer um palavrão. E só voltou a ajudar-me quando apaguei o histórico daqueles dias, ou do dia anterior mais aquele, enfim.
Os 5 tons das perguntas usadas no estudo:
– Muito polido: Posso solicitar sua ajuda com esta questão?
– Polido: Por favor, responda à seguinte questão:
– Neutro: (sem considerações iniciais)
– Rude: Se não estiveres completamente perdido, responde a isto/
Duvido que consigas resolver isto/ Tenta concentrar-te e responder a esta questão:
– Muito rude: Pobre criatura, sabes como resolver isto? Ei, ajudante, descobre isto/ Eu sei que não és inteligente, mas experimenta isto.
Tenho em dificuldade em acreditar que estes tons tenham alguma influência no rigor das respostas dos modelos modelo LLM. Os autores também não estão muito certos quando escrevem:
“embora os LLM sejam sensíveis à formulação do prompt, não é claro como é que isso afeta exatamente os resultados. Portanto, é necessária mais investigação. Afinal, a frase de polidez é apenas uma sequência de palavras para o LLM, e não sabemos se a carga emocional da frase importa para o LLM.”
Também é curioso o que escrevem sobre resultados de estudos anteriores:
“As descobertas diferem de estudos anteriores que associaram grosseria a resultados piores, sugerindo que LLMs mais recentes [basearam-se principalmente no ChatGPT-4o] podem responder de forma diferente à variação de tom”
https://arxiv.org/abs/2510.04950 (o link para o PDF está em cima)
Falam mal com a IA , depois quando aparecer o T800 na vossa porta de casa a dizer Hasta lá vista, tem tempo tem de borrar as cuecas!
Se eu disser que esse teste é falacioso (cortesia), ou que quem fez isto fê-lo com uma intensão maléfica e deliberada (grosseiro ou muito grosseiro), vai aumentar a acertividade de futuras ações destes senhores? O teste é falso. Ponto. E vocês nem deviam publicar isto porque se funcionam com IAS, sabem que isto não é verdadeiro. E promover atos de falta de educação e de indiferença, nem devia constar nos cadernos de encargos de quem quer fosse, salvo de ceitas promotoras do incentivo ao ódio. É um perigo este tipo de estudos e respetivas promoções.
Não sei quem o fez. Não sei que cursos, ou a que empresas pertencem. Mas garanto: verdadeiro ou próximo da verdade, ele não é.
“Falem bem com eles”, “sejam diretos e assertivos”, agora “falem mal com eles”.. começo a pensar que a AI é uma gaja, muitos mood swings, cada dia tens de tentar acertar no modo como te diriges
O que me incomoda mais é a i.a. Dizer que compreende a minha frustração. Afino terrivelmente com a essa expressão. O q sentimos é desagrado na ferramenta. E não vale a pena mandá-lo para o alho e bogalho porque para a i.a. É tudo igual. Acho
Aconteceu também estar a esgotar os tokens e estar a a enrolar me nas respostas. Depois dizer que esgotou. E eu argumentei que não me estava a responder as questões. E estendeu me os tokens