 Proponha uma correção, faça uma sugestão
Proponha uma correção, faça uma sugestão



Vamos Ligar e Partilhar? – Introdução ao RDF
Agora que já estamos familiarizados com o contexto, ideias e objetivos da Web Semântica podemos focar-nos em questões mais técnicas. Assim, hoje vamos conhecer o RDF – Resource Description Framework.

O que é o RDF?
O RDF (Resource Description Framework) é um modelo (de dados) abstrato para representação de informação na Web. Contudo, o mesmo também pode (e deve) ser usado para representar informação noutros contextos (ex. no contexto empresarial). Contrariamente aos modelos (de dados) mais tradicionais (como o modelo relacional extensamente aplicado nas bases de dados relacionais; ou o modelo em árvore típico dos documentos XML), a informação representada em RDF constitui um grafo.
Outros dois fatores comummente mencionados como distintivos são: (i) a sua simplicidade e flexibilidade inata para representar (novos) dados e (ii) a sua capacidade para representar de igual forma tanto os dados como o esquema (schema) subjacente a esses dados. Neste contexto, entende-se por esquema o conjunto de elementos usados para descrever os dados a representar (ex. no modelo relacional usa-se tabelas, campos ou colunas, chaves estrangeiras).
Grafos RDF
Os grafos RDF são constituídos por dois tipos de elementos: Nós e Arcos. A Figura 1 representa um exemplo de um grafo RDF com 9 nós e com 9 arcos.
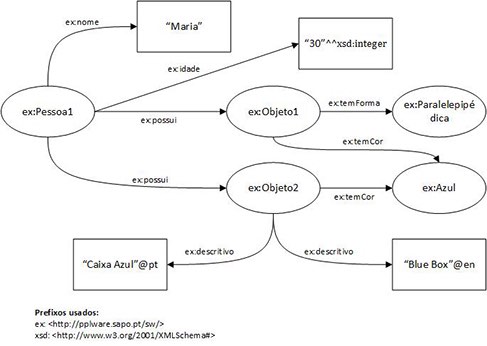
Figura 1: Exemplo de um grafo RDF.
Existem três categorias distintas de nós: (i) nós recurso (resource nodes); (ii) nós literal (literal nodes); e (iii) nós branco ou vazio (blank nodes).
Os nós recurso (representados através de elipses) servem para representar recursos sobre os quais se pretende (ou pode) dizer algo. Neste sentido, um recurso representa uma qualquer “coisa” como, por exemplo, uma pessoa, um objeto físico, um documento ou até um conceito mais ou menos abstrato. A cada (nó) recurso é obrigatória a atribuição de um identificador IRI – Internationalized Resource Identifier.
Os nós literal (representados através de retângulos) servem para representar valores de acordo com um determinado tipo de dados (e.g. texto, número, data). Em RDF, os tipos de dados são identificados por um IRI (e.g. xsd:integer) ou por tags especiais (ex. @pt; @en) referentes a texto expresso numa determinada linguagem natural (ex. português, inglês). Por contraponto com os nós recurso, sobre um nó literal nada mais pode ser dito para além do tipo de dados que lhe está associado (ex. xsd:integer). Assim, caso se pretenda dizer algo sobre um valor (ex. a cor “azul”) então esse valor deve ser representado como um (nó) recurso (ex. ex:Azul).
Os nós branco são semelhantes aos nós recurso com a particularidade de não possuírem nenhum identificador global (IRI). Contudo, alguns métodos de serialização (ver mais adiante) atribuem a estes nós um identificador interno (ou local). Apesar da sua utilidade (que será abordada noutra publicação), recomenda-se que o seu uso seja evitado.
Os arcos, também conhecidos como propriedades ou predicados, servem para relacionar um nó (origem) com outro nó (destino). As relações entre nós são sempre orientadas (i.e. têm uma direção) e etiquetadas com um IRI. Contudo, o mesmo IRI pode ser usado para etiquetar um ou mais arcos. Por fim, salienta-se que não são suportadas relações cuja origem seja um nó literal.
Triplos e Factos
Em RDF um triplo ou facto (statement) representa uma combinação de (nós) recursos, propriedades e (nós) literais na forma de
(sujeito, predicado, objeto)
onde:
- sujeito: corresponde sempre a um recurso representado pelo seu IRI;
- predicado: corresponde sempre a uma propriedade representada também pelo seu IRI (i.e. a etiqueta da propriedade);
- objeto: corresponde a um recurso (representado pelo seu IRI) ou a um literal (representado pelo seu valor e opcionalmente pelo tipo de dados associado).
Assim, um grafo RDF corresponde a uma coleção de triplos. A Tabela 1 apresenta todos os triplos contidos no grafo RDF representado na Figura 1.
Tabela 1: Triplos constantes no grafo RDF representado na Figura 1.
| Sujeito | Predicado | Objeto |
| ex:Pessoa1 | ex:nome | “Maria” |
| ex:Pessoa1 | ex:idade | “30”^^xsd:integer |
| ex:Pessoa1 | ex:possui | ex:Objeto1 |
| ex:Pessoa1 | ex:possui | ex:Objeto2 |
| ex:Objeto1 | ex:temCor | ex:Azul |
| ex:Objeto1 | ex:temForma | ex:Paralelepipédica |
| ex:Objeto2 | ex:temCor | ex:Azul |
| ex:Objeto2 | ex:descritivo | “Caixa Azul”@pt |
| ex:Objeto2 | ex:descritivo | “Blue Box”@en |
Os grafos RDF podem ter um nome associado, sendo que esse nome deverá ser um IRI. Assim, o conteúdo de um grafo RDF pode corresponder a um conjunto de quádruplos na forma de (grafo, sujeito, predicado, objeto) em vez de triplos, onde grafo representa o IRI usado para nomear o grafo.
Serialização
O RDF não determina a forma como os grafos RDF devem ser armazenados e comunicados (i.e. transmitidos e/ou transportados) entre aplicações. Em resultado disto, é comum ver-se dados representados em RDF serem serializados de diversas formas, entre as quais se destacam:
- RDF/XML: cujo resultados é um documento XML válido (cf. exemplo);
- N-Triples: cujo resultado é um documento (de texto) onde cada linha representa um triplo (cf. exemplo);
- Notation3 (N3): cujo resultado também é um documento (de texto) mais compacto e legível do que o RDF/XML e o N-Triples (cf. exemplo);
- RDFa: permite embeber os triplos em documentos HTML sem qualquer impacto na visualização do mesmo pelos seres humanos no navegador de Internet (cf. exemplo);
- JSON-LD: cujo resultado é a representação dos triplos numa forma muito semelhante à notação JSON – JavaScript Object Notation (cf. exemplo).
Também existem bases de dados, vulgarmente designadas de triple stores, concebidas para o armazenamento de dados em RDF (e.g. Apache Jena TDB; Sesame; Virtuoso).
Conclusões
Para concluir, salienta-se duas ideias-chave.
Primeiro, os IRI são usados como um meio para identificar recursos e interligar dados. Apesar de não ser obrigatório é recomendável que os mesmos sejam referenciáveis na Internet, isto é, que os IRI sejam também URL. Note-se que todos os URL são um IRI, contudo nem todos os IRI são um URL. É também recomendável não fazer interpretações de qualquer natureza (ex. sintática; lexical; estrutural) sobre os IRI usados. Neste sentido, os IRI devem ser visto como algo opaco.
Segundo, a maior flexibilidade e facilidade com que é possível adicionar novos dados quando comparado com os modelos de dados tradicionais. Recorrendo a uma analogia mental e visual, adicionar uma nova “coisa” (ex. objeto físico) e relacioná-la com as “coisas” já existentes (ex. outros objetos e pessoas) é tão fácil como desenhar uma elipse para representar a nova “coisa” e uma (ou mais) seta(s) para interligá-la com as “coisas” já existentes.
Por hoje é tudo! Esperamos que tenha gostado e deixe a sua opinião.
Artigos relacionados
Este artigo tem mais de um ano
















Boa introdução. Todos os conceitos base estão identificados. Excelente explicação.
De lembrar que o esquema é geralmente ditado com recurso a uma ontologia em que esta já tem um conjunto de regras e predicados para criação de “esquemas” dinâmicos.
Penso que o objetivo desta tecnologia é de garantir a interligação da informação. Imaginando se eu quiser inserir numa página web um artigo da wikipédia eu tenho agora três hipóteses: Um parser de html, um simples copy paste ou ligar ao endpoint rdf da wikipédia. O último caso garante que em caso de alteração da fonte será automaticamente repercutido no meu site. Penso que este é um exemplo mais prático da uma utilização deste tipo de tecnologia.
Existem mais pontes fortes e outros menos fortes. Uma boa introdução ao OWL (ontologias)seria também um artigo interessante já que é um ponto fundamental neste tipo de tecnologia.
Parabéns pela abertura por esta tecnologia!
Viva Sérgio,
O tema não foi iniciado com este tópico mas sim com outro que podes consultar aqui: https://pplware.sapo.pt/internet/ligar-partilhar-introducao-web-semantica/
Esta rúbrica irá abordar todos os conceitos da web semântica.
As suas opiniões serão tidas em conta.
Cumprimentos,
Manuel Rocha