 Proponha uma correção, faça uma sugestão
Proponha uma correção, faça uma sugestão


Chinesa DeepSeek estará a “enganar” o mercado IA
A IA chinesa DeepSeek abalou o mundo da IA porque, em teoria, era um LLM muito avançado que teria custado apenas 6 milhões de dólares no total. Os números apresentados davam uma "chapada de luva branca" à tecnologia da americana OpenAI. Contudo, o Bom, Bonito e Barato... afinal poderá ser mentira!

DeepSeek é muito mais cara do que o anunciado
Sim, o cenário parece ser extraordinário, aliás, segundo os números apresentados, talvez até demasiado bom para ser verdade. Os dados de um estudo partilhado pela SemiAnalysis confirmam que tudo não passou de uma ilusão em que muitos quiseram acreditar.
O estudo baseia-se num ponto crucial: o custo do hardware necessário para treinar o DeepSeek. Para este treino, foram usadas GPUs da NVIDIA, mais precisamente modelos H800 e H100, cujo custo total ronda os 1.600 milhões de dólares. A isto, soma-se o custo operacional de manter e utilizar essas GPUs, estimado em cerca de 944 milhões de dólares.
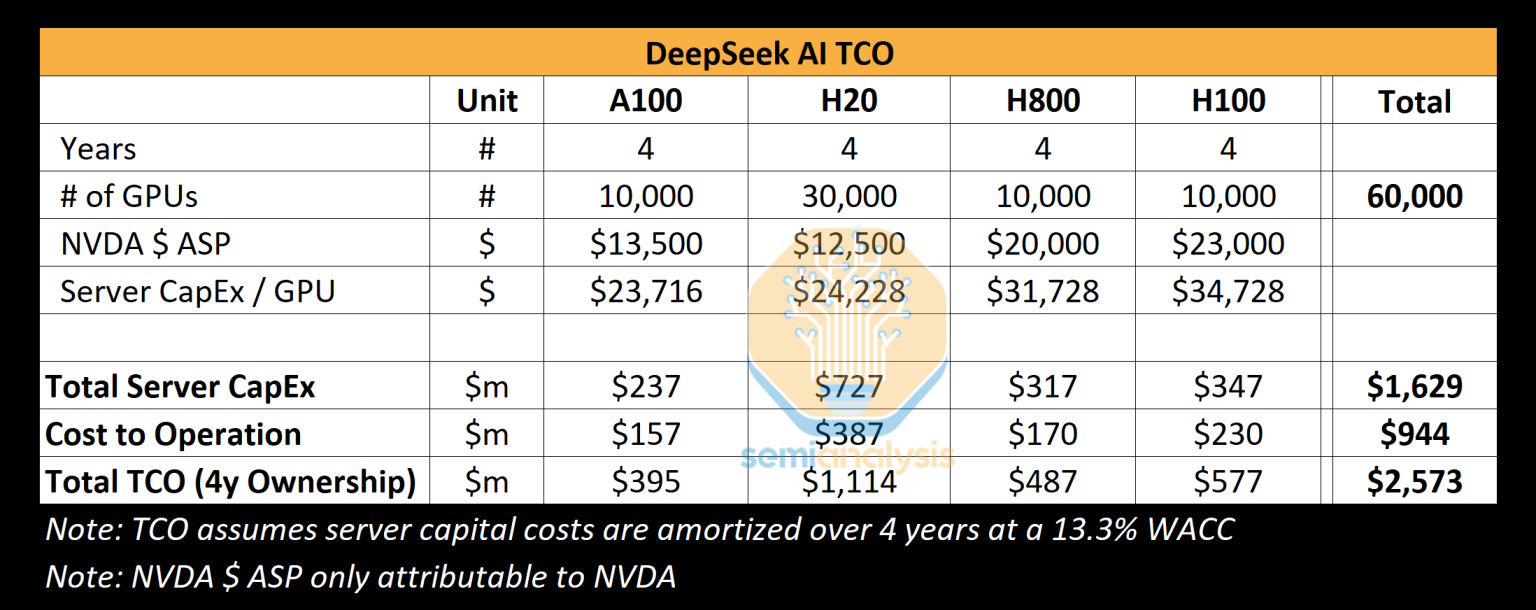
No total, para treinar o DeepSeek, terão sido utilizadas cerca de 60.000 GPUs da NVIDIA, resultando num custo acumulado de aproximadamente 2.573 milhões de dólares, segundo a SemiAnalysis. Além disso, há outro fator importante a considerar: o custo dos dados necessários para alimentar um modelo desta dimensão.
De acordo com as informações mais recentes, os responsáveis por esta IA podem ter roubado dados da OpenAI e treinado o DeepSeek com uma técnica conhecida como destilação de resultados. Este método viola as políticas de uso da API da OpenAI, mas permite reduzir significativamente os custos de treino de uma IA.
Os tais 6 milhões de dólares referem-se apenas ao custo em GPUs na fase de pré-treino, o que representa uma pequena fração do custo total do modelo. Este valor ignora despesas fundamentais como os investimentos em I&D e o custo total de propriedade do hardware.
Em resumo, o valor divulgado não reflete o custo real. Além disso, o facto de o DeepSeek ter conseguido acesso a um número tão elevado de GPUs para treinar a sua IA levanta questões sobre a eficácia das restrições de exportação deste tipo de hardware para a China, um tema que já está a ser investigado.
IA chinesa será assim tão impressionante?
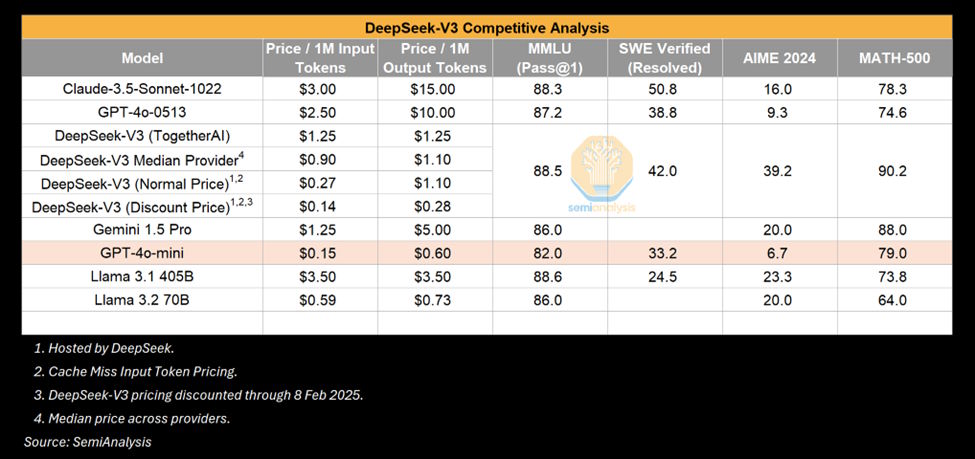
Tecnicamente, representa um avanço importante na inteligência artificial, mas isso depende da comparação. Em termos de custo por milhão de tokens, oferece um bom valor face a certos modelos, como o GPT-4o-0513, mas fica atrás do GPT-4o-mini e do Llama 3.2 70B.
Resta ver como este tema vai evoluir e qual será o desfecho da polémica gerada em torno deste modelo. No entanto, uma coisa é certa: a chegada do DeepSeek deverá intensificar a concorrência entre modelos de IA avançada, algo que poderá ter um impacto positivo no setor.
Este artigo tem mais de um ano















Foi dado autorização ao mais alto nível na América para operações de narrativa…
O que sabemos é que a comunidade adorou o opensource e já existe um monte de projectos baseados nas LLM deepseek algo que não se poderia fazer com OpenAI que de Open só tem nome…
Até a Microsoft vai adoptar o mesmo para incorporar nos equipamentos com copilot+.
+1
Ou seja, qualquer um pode fazer um LLM, isso é bom ou mau? Não me parece bom, estamos a manusear uma força equiparada ao nuclear. Para começar é bom saber quem, depois onde e o quê (finalidade).
como assim força equiparada á nuclear ?
o motor de busca também é uma força igual á nuclear ?
Na Mouch
sabem cuantas NVIDIA 4080 havia na china a minar cryptos?
as mesmas que ha uns meses estavao a vende-las a peso?
será que usaram esses chips?
e 100 nvidia 4080 fazem o mesmo que uma h800? (nao sei qual a relaçao)
Supostamente ninguém sabem quantas máquinas há a minar crypto na China. Dá cadeia. É bom que ninguém saiba mesmo…
“treinado o DeepSeek com uma técnica conhecida como destilação de resultados. Este método viola as políticas de uso da API da OpenAI” – isto é caso para dizer: “Ladrão que rouba ladrão tem cem anos de perdão.”
A controvérsia em torno da DeepSeek e das alegações de que ela seria um “plágio” do ChatGPT é um tema complexo, mas eu não concordo com essa ideia. Vamos analisar esse cenário com base em alguns pontos importantes:
Semelhança não significa cópia
O fato de o DeepSeek utilizar métodos ou técnicas similares para treinar o seu modelo de linguagem não implica, automaticamente, que ele copiou o algoritmo do ChatGPT. Comparar o DeepSeek ao ChatGPT é como comparar a fórmula secreta da Coca-Cola com outras bebidas de sabor similar: pode haver semelhanças no produto ou no processo, mas a fórmula exata permanece protegida. O algoritmo do ChatGPT nunca foi divulgado publicamente, o que torna impossível replicá-lo de forma idêntica.
As empresas que confiaram no DeepSeek
Outro ponto crucial é que empresas de grande relevância tecnológica, como Nvidia, Microsoft e Meta, integraram o DeepSeek aos seus serviços. Se a tecnologia fosse, de fato, tão “ruim” ou baseada apenas em cópia, seria difícil imaginar que empresas tão importantes, com acesso a recursos e especialistas, apostariam na DeepSeek. Essas organizações não tomam decisões estratégicas sem análises detalhadas, o que reforça a legitimidade do modelo.
A controvérsia da destilação de resultados
Embora existam acusações de que a DeepSeek utilizou a técnica de destilação de resultados para treinar seu modelo, é importante lembrar que essa abordagem, apesar de polêmica, não significa necessariamente “roubo” de tecnologia. Ela pode ser uma forma de aprendizado baseada nos outputs de outro modelo, mas isso não equivale a replicar o código ou o algoritmo subjacente.
Impacto no setor e a intensificação da concorrência
A chegada do DeepSeek está ajudando a intensificar a concorrência no setor de inteligência artificial, o que é extremamente positivo para o avanço da tecnologia. Modelos como o ChatGPT, Llama 3.2 e o próprio DeepSeek estão se desafiando mutuamente, o que beneficia os consumidores e acelera o desenvolvimento de soluções mais acessíveis e eficientes.
Conclusão
Não acredito que seja “fácil” copiar a tecnologia do ChatGPT, pois os algoritmos e as arquiteturas por trás desses modelos são altamente protegidos e complexos. A comparação entre DeepSeek e ChatGPT deve ser baseada em resultados e inovação, e não em teorias de plágio. Afinal, a verdadeira concorrência no setor de IA está na capacidade de cada empresa oferecer soluções únicas e eficazes – e não em acusações infundadas.
As críticas e rumores podem ser inevitáveis, mas o tempo dirá se a DeepSeek realmente merece ser vista como um competidor à altura. Até lá, é importante avaliar as tecnologias com base em fatos e resultados, e não apenas em suposições.
“O fato de o DeepSeek utilizar métodos …”, deveria ter escrito “O facto de o DeepSeek utilizar métodos …”.
Em português de Portugal o “c” quando é pronunciado, não desaparece.
Em Portugal fato, é de vestir, no Brasil diz-se “terno”.
Como por exemplo “contacto” e não “contato” que é como se diz no Brasil.
Também deve dizer “pacto” e não “pato”.
Eu sei que o acordo ortográfico só veio complicar em muitas coisas, mas nestes casos é muito explícito – pronuncia-se, logo escreve-se.
O ser humano replicas-se por isso somos todos deferentes todos iguais…
Este local está cheio de atentados à língua portuguesa:
“O ser humano replicas-se”??? Quanto muito o ser humano replica-se. Mas se ele se replicasse seriamos todos iguais e não diferentes. Deferente sou para com alguém mais importante do que eu.
O Fernando Pessoa deve estar aos saltos na campa com tanta calinada na língua!
Ainda não passou um mês e já chegaram à conclusão que afinal o investimento é muito superior ao divulgado, que usaram milhares de GPU’s e gastaram milhões de dolares.
Também não incluíram todas as despesas nas suas análises.
Também não incluíram os custos dos dados que afinal foram roubados da OpenAI.
Mas afinal em que ficamos… se foram roubados não tiveram custos ou se tiveram custos não foram roubados… ou um ou outro!!!
Mais uns dias e vão chegar à conclusão que utilizaram mais GPU’s do que aquelas que foram fabricadas.
Conclusão: A DeepSeek o que precisa é de um contabilista.
Curiosidade. No site da SemiAnalisys não refere o país origem nem onde são os escritórios centrais ou sede. Pesquisem por: de que país é a semianalisys
Mas se pesquisarem por: Andrew Lekashman in linkedin– SemiAnalysis já aparece Lekas (Andrew Lekashman – SemiAnalysis) trabalha em Los Gatos, California, United States · SemiAnalysis Andrew Lekashman. SemiAnalysis San Diego State University-California State University. Los Gatos, California, United States.
Portanto temos de falar com o Lekas
Mesmo quando você rouba um código, para o usar, noutra coisa, terá de perder tempo ou contratar, mais pessoas, para conseguir utilizar o dito código. Isso é um custo. Se a Deepseek usou 830000 jovens chineses, estudantes, para treinar a AI, para eles o custo foi zero… mesmo que o código seja de outros. Só que o proprietário, da empresa, recebeu 46000 milhões de Yuan (já confirmado, pelo governo chinês) para desenvolver um motor de busca, AI, que pudesse obter resultados, mais rápido, que a Google e que pudesse responder a, algumas, perguntas utilitárias. Foi, depois disso, estar feito, que criaram rotinas, que bloqueiam, quaisquer respostas, que não sirvam para o governo chinês. Tudo isso são custos, que não aparecem. Além de não se saber se é mesmo verdade que usaram 80000 pentabytes, durante 8 a 17 meses, para treinar a AI, a reconhecer perguntas, mais avançadas. A empresa não desmentiu que terá usado, essa capacidade, mesmo sem revelar onde o fez e quem pagou.
Com tantos Chineses espalhados pelo mundo fora, certamente não deve ser muito complicado comprar o material nesses países e enviar para a China, ou o países aliados da China ajudarem também, todos sabemos onde há dinheiro há corrupção e a corrupção não conhece fronteiras.
A tua perspectiva é limitares-te a propagandear aquilo que ouves sem conhecimento de causa! A China nos últimos anos tem registado mais patentes que os EUA e UE juntos! Saberás o que é isso?…
Qual propaganda, eu tenho olhos e sentido critico e conheço o mundo que me rodeia, ao contrario de muitos que o mais longe que foram foi ao Algarve.
Propaganda é coisa de ditaduras e a China caso não tenhas reparado é uma ditadura.
Queres tu dizer que propaganda é coisa só do ocidente?
Falam da China como se fosse um país fantástico e cheio de liberdades, o que eu acho mais engraçado é ouvir pessoas a defender a China coisa que não podiam fazer caso a nossa influência não fosse os EUA, se fossemos influenciados pela China e companhia nem acesso livre a internet tinhas, mas pronto propaganda é só no ocidente.
Caro B@rão Vermelho,
É sempre fascinante ver alguém com uma visão tão clara e crítica do mundo, especialmente de um país onde alegas ter ido muitas vezes, mas aparentemente nunca saíste do aeroporto. Como é que consegues conhecer melhor a China, então? Será através das informações obtidas a partir do primo de terceiro grau do vizinho, que conheceu um primo do amigo? A tua capacidade de resumir séculos de história e política em poucas linhas é verdadeiramente impressionante. Já pensaste em escrever um livro? Algo como ‘A China para Leigos’, talvez.
Sabemos todos que a corrupção não conhece fronteiras. É por isso que nunca se ouve falar de escândalos de corrupção no Ocidente, certo? Porque aqui, claro, os nossos líderes são bastiões da integridade.
Falaste também sobre a falta de acesso livre à internet na China. É fascinante como conseguiste navegar por esses mares proibidos e voltar com todas essas percepções. Deve ser essa tua ‘visão crítica’ que te permite ver o que nós, meros mortais, não conseguimos.
E se a China é tão ditatorial, como explicas que os turistas chineses, que são alguns dos principais fomentadores do turismo mundial, ainda regressem ao seu país? Se fosse assim tão terrível, já tinham fugido, não achas? Ah, e não confundas com os emigrantes chineses espalhados pelo mundo. Afinal, nós portugueses também estamos espalhados pelo mundo, e nem por isso isso faz de Portugal um país terrível.
Com admiração,
+1
Ele tem uma visão afunilada do mundo em que vive…
O teu mundo deve ser o do Portugal dos Pequenitos. Apenas parcial o teu sentido critico (apenas propaganda). Aconselho- te a procurares o contraditório para abrires a mente!…
PAra alguém “novo” nestas andanças da IA – a tecnica de destilação de resultados para treinar o deepsleek, não é “propagar o erro”?
O ChatGPT não é nada mau mas comete erros (alguns complicados) e treinar uma IA com base no output de outro modelo não é aumentar o erro na “segunda iteração”? Ou seja, no final o modelo pode até ser tecnicamente poderoso mas a nivel de resultados poderá ter menos qualidade – como se diz em analise de dados “Garbage in –> garbage out” e aqui duplicamos o primeiro.
no inicio do anuncio disse-o e continuo a dizer. Deixem a poeira acentar e depois podemos tirar as reais conclusões.
Os chinos sempre nos habituaram a fazer copia bem feitas por menos cvstos, so compra e utiliza quem quer, eu ca de IA ja sou velho demasiado para utilizar essas porcariasm mas ainda vai dar muito que falar.
Mas quem é que acreditou em tal proeza? XD
Claro que foi para manipular o mercado financeiro.
As baleias compraram ações da Nvidia 20% mais baratas.
Os chineses têm pessoas infiltradas por tudo quanto é lugar, como têm os israelitas na cisjordania, era so questao de dias, eles imitam bem mas certos produtos deixam muito a desjar em termos de qualidade, na minha perspectiva.
A tua perspectiva é limitares-te a propagandear aquilo que ouves sem conhecimento de causa! A China nos últimos anos tem registado mais patentes que os EUA e UE juntos! Saberás o que é isso?…
E logo apareceu um dos infiltrados que por aqui anda a defender a causa chinesa. Mas este até comentários duplica… deve ser para ter menos trabalho. É compreensível, o Xi Jipingas paga pouco.
Olá, jorge e Ralosc! Que comentário tão profundo e cheio de teorias intrigantes. A vossa capacidade de identificar “infiltrados” é realmente digna de um filme de espionagem, daqueles com orçamentos baixos e diálogos previsíveis. E claro, como não mencionar o icónico “Xi Jipingas”? Um insulto tão elaborado que quase parece que se inspiraram em algum fórum obscuro da internet. Brilhante!
Agora, sobre a questão da “qualidade” dos produtos chineses — vamos aos factos, porque a vossa análise parece basear-se naquele clássico “ouvi dizer”. Se os produtos chineses fossem assim tão maus, como explicam que a União Europeia e os Estados Unidos precisem de impor sanções, taxas, impostos e até embargos aduaneiros contra produtos de tecnologia chinesa? Empresas como Huawei, Xiaomi, Lenovo, e BYD não estão a ser bloqueadas porque fazem produtos “deixam muito a desejar”, mas sim porque estão a competir diretamente com gigantes tecnológicos ocidentais. É irónico, não acham? Se os produtos fossem tão “ruins”, como dizem, bastava deixá-los no mercado e confiar no bom senso dos consumidores europeus, que certamente os ignorariam. Mas o que vemos é precisamente o contrário: a própria União Europeia reconhece a qualidade e o preço competitivo dos produtos chineses e sente necessidade de intervir para proteger as suas próprias indústrias. Não é nada pessoal, apenas negócios.
Sabiam que, só em 2023, a China registou mais de 1,4 milhões de patentes, superando os Estados Unidos e a União Europeia combinados? Isso reflete uma economia que não só “copia”, como sugerem, mas que também inova a um ritmo impressionante. Empresas como Huawei, por exemplo, são líderes em tecnologias como 5G — uma área onde muitos países ocidentais ainda estão a tentar acompanhar. Ou será que acham que essas patentes também fazem parte de uma conspiração global para vos enganar?
Ah, e sobre duplicar comentários ou “ter menos trabalho”… talvez isso seja apenas um reflexo da vossa própria argumentação, que parece um disco riscado cheio de clichés. Já pensaram nisso? Pode ser que o “eco” venha do lado de quem aponta dedos sem qualquer fundamento. Afinal, repetir “eles copiam, infiltram-se e fazem produtos ruins” não melhora a validade das vossas opiniões.
Por fim, enquanto distribuem acusações de propaganda, não será interessante considerar se a vossa visão limitada e generalista não está a repetir outro tipo de narrativa — uma que ignora a realidade de um país que produz tanto inovação como concorrência?
E aqui vai um detalhe curioso para refletirem: ao postarem esses comentários infantis, vocês estão, ironicamente, a usar PCs, tablets ou telemóveis fabricados pela China e/ou com peças feitas lá. É engraçado pensar que estão a criticar, mas ao mesmo tempo dependem da tecnologia chinesa para o fazerem. Não acham isso ligeiramente incoerente?
Não gostou do “Xi Jipingas”? Reclame com os lituanos.
Ah, claro, os lituanos! Como não pensei nisso antes? Mas agora fiquei na dúvida: será que os lituanos estão cientes da responsabilidade cósmica que lhes atribuíste, ou seria mais justo culpar os marcianos? Afinal, se há alguém com mão em tudo, só pode ser o pessoal lá de Marte. Eles têm essa habilidade incrível de criar apelidos brilhantes como ‘Xi Jipingas’ enquanto gerenciam conspirações intergalácticas. Grande gestão de tempo, não achas?
Mas, acusar os lituanos de criar apelidos brilhantes em português é muito criativo. Eu não sabia que os lituanos falam e escrevem português! Isso abre um mundo de possibilidades! Talvez seja hora de revermos os nossos preconceitos linguísticos — quem diria que o próximo Camões poderia estar escondido na Lituânia?
Olha, tenho que te dar crédito: é preciso muita coragem para entrar numa discussão destas e oferecer… isso. Tens um talento especial para desviar o foco da conversa, transformando-a numa aula de geografia interplanetária. Bravo, Ovni em bico, o teu comentário foi tão profundo quanto uma poça d’água num dia de sol. Espero que os marcianos apreciem o teu esforço, pois parece que os lituanos já se demitiram da missão.
Compreendo o seu ponto de vista. A expressão de opiniões deve sempre ser baseada em factos e não em preconceitos.
+1
Mais um sinofóbico que se alimenta de narrativas, mas sem qualquer conhecimento de causa. Para argumentário semelhante resposta semelhante!
O conhecimento é demasiada areia para determinadas pessoas…
Mais um com os …fóbicos sempre a jeito de atirar àqueles com que discorda.
Há demasiado fumo à volta dos 5,6 milhões. O que a fonte do post faz é dizer o custo do treino do modelo, que terá sido de 5,6 milhões é diferente do custo total de investimento e despesas de funcionamento durante 4 anos da DeepSeek, que estima em 2,6 mil milhões.
Aqui a questão é que o conceito de custo de treino de um modelo existe. Vi, por exemplo o custo de 60 milhões no treino do último modelo da Meta. E que o custo do treino do ChatGPT 3, de 2020, da OpenAI, andou entre os 5 e os 12 milhões.
O que me parece é que foi criada uma confusão entre os milhões do custo do treino de um modelo e os milhares de milhões em custos de investimento e de funcionamento, durante vários anos, das empresas que o desenvolve (e no mesmo período desenvolve outros modelos e produtos, chegando os custos totais aos milhares de milhões).
Ilusão ilusão é acreditar nestes estudos encomendados pelos EUA para denegrir a imagem de algo que esta a funcionar e bem melhor que os chatgpt s que por aí andam….
isto! o verdadeiro MVP.
Este tipo de comentário é parecido com aqueles que se viam durante o covid-19 – em que a malta apenas acredita no que convém 😀
Peter Griffin joins in with: Oh my god who the hell cares.
A verdade é que os pesos estão disponíveis para o uso de quem quiser e isto marca um ponto de viragem no blablabla todo sobre as LLMs. Financeiramente isto é a desgraça da OpenAI. E ainda bem.
Não morro de amores pela openai, muito pelo contrário. No entanto, é só mais um LLM, tem o impacto á imagem do que tiveram os llama,Mistral,command-r,Yi,qwen,phi,wizardlm,zephyr,etc. Geraram hype mas foram ultrapassados numa questão de meses. Quando a OAI lançar o seu próximo modelo, este ficará para trás no esquecimento. Na verdade os pesos são abertos mas quem é que corre isto de forma a tirar partido do mesmo de forma a compensar os custos?
A mistral Francesa lançou uma open source na semana passada muito boa, acima da média para o seu tamanho. Consigo rodar numa GPU de 16 GB ainda com espaço . Nas avaliações equipara-se com as versões de 70B llama 3.3 e qwen 2.5. Mistral small 2501. Full precision tem 24GB, mas quantizada a Q4-KM fica com 14 GB. Parece não perder precisão nesta quantização. É preciso colocar a temperatura da LLM a 1.5. responde factualmente muito bem, é um pouco seca nas respostas. Aqui as avaliações: https://mistral.ai/news/codestral-2501/.
Nos repositórios tem o nome de mistral mini 2501 ou mistral mini 3
O velho ditado mantém-se… “Quando é bom e barato, é para desconfiar”.
E então vindo dos chinocas…
A China está a dar cartas em todos sentidos
A informação que o DeepSeek disponibiliza é anterior a setembro de 2023 porquê?
Experimentem perguntar “que dia, mês e ano é hoje?”
Responde 04/02/2025 😉
Leste isso em qualquer lado, para modelos ofline. Mas isso é o mesmo em modelos conhecidos que, combinam dados com que foram treinados, com dados, atuais que recolhem da internet.
Se puseres o ChatGPT e o DeepSeek ofline ambos dizem que Joe Biden é o presidente dos EUA. Se os puseres online dão a resposta correta.
Já agora … Os bons modelos estão protegidos contra ataques de desinformação que possam surgir em informação recente na net, avaliando a sua consistência com os dados que já possuem e estão validados. Há quem diga que é por isso que quando se pergunta que dados estão a utilizar dêem uma data antiga. O DeepSeek, na app do smartphone diz julho de 2024.
Experimentaste perguntar-lhe o porquê?
A data de cut-off (essa é que interessa ao utilizador, e a data em que finalizou o treino mais recente do modelo de linguagem) do DeepSeek é Julho de 2024.
Por curiosidade, a do ChatGPT é Junho de 2024, ainda antes do DeepSeek.
A data de cut-off previne que os modelos de linguagem saibam informações atuais, pós essa data.
Coloquei a questão a um e outro, e o DeepSeek apresentou a data atual de 23 de Outubro de 2023, enquanto o ChatGPT deu a data correta. O DeepSeek, quando confrontado com a disparidade entre a data atual fornecida e a real, reconheceu o engano, e informou que não tem como saber a data real porque não tem um relógio interno. Já o ChatGPT informou que tem acesso a um relógio interno, e portanto consegue indicar a data atual mesmo sem acesso a referências externas após a sua data de cut-off.
Nem tudo é uma conspiração. Ambos são software, com bugs, uns aqui, outros ali.
Correcto. Uma das coisas apontadas a muitas LLM opensource é não serem muito conscientes sobre si mesmas. Aliás, o seu objectivo é responder da melhor forma possível sobre as matérias dos datasets que foram treinadas. Há muitos reports com apontamentos do género em quase todas. E com razão, a informação sobre elas mesmas é pouco relevante para a maior parte das pessoas. O cutoff data limita eventuais conhecimentos sobre o presente, mas este é o calcanhar de Aquiles de muitas LLMs a funcionar offline . Já existem alguns estudos sobre futuras AI capaz de aprenderem novas informações sem depender de novo treinamento ou fine tunnings tipo Qlora. Ou seja, uma IA capaz de evoluir e Aprender sem ter o processo penoso de backpropagations dos TODOS os seus weights.
Os chineses apenas quebraram as regras de utilização da outra app para sacar as informações da outra, informações essas que os americanos roubaram a todos nós e estão a tentar fugir com o rabo à seringa…
o llm portugues amalia tambem vai ser assim ?
o governo diz que custa uns trocos e depois vamos ver e custou milhoes ?
Começou a narrativa ocidental para deitar abaixo os produtos chineses…
este artigo é propaganda americana para tentar salvar a openai e a NVIDIA do descalabro.
Tal como o teu comentário é propaganda chinesa para te entrar uns cobres no bolso. 😀
Não inventem.
Humanos-servidores-base de dados-AI 🙂