 Proponha uma correção, faça uma sugestão
Proponha uma correção, faça uma sugestão



Dica: Como executar o modelo Deepseek-R1 localmente no seu computador Windows
O DeepSeek-R1 destaca-se por várias razões. Além de ser open-source, demonstra uma elevada capacidade de resolução de problemas, raciocínio e programação. Vamos explorar como pode executar este modelo localmente e offline na sua máquina.

Hold my beer!
Passo 1: Instalar o Ollama
Antes de avançarmos, é importante falar sobre o Ollama. Trata-se de uma ferramenta gratuita e open-source que permite a execução de modelos de Natural Language Processing (NLP) localmente. O Ollama torna o download e execução do DeepSeek-R1 um processo simples e intuitivo.
Portanto, o primeiro passo é fazer o download do executável (ocupa cerca de 745 MB). Aceda ao site oficial do Ollama e clique em "Download".
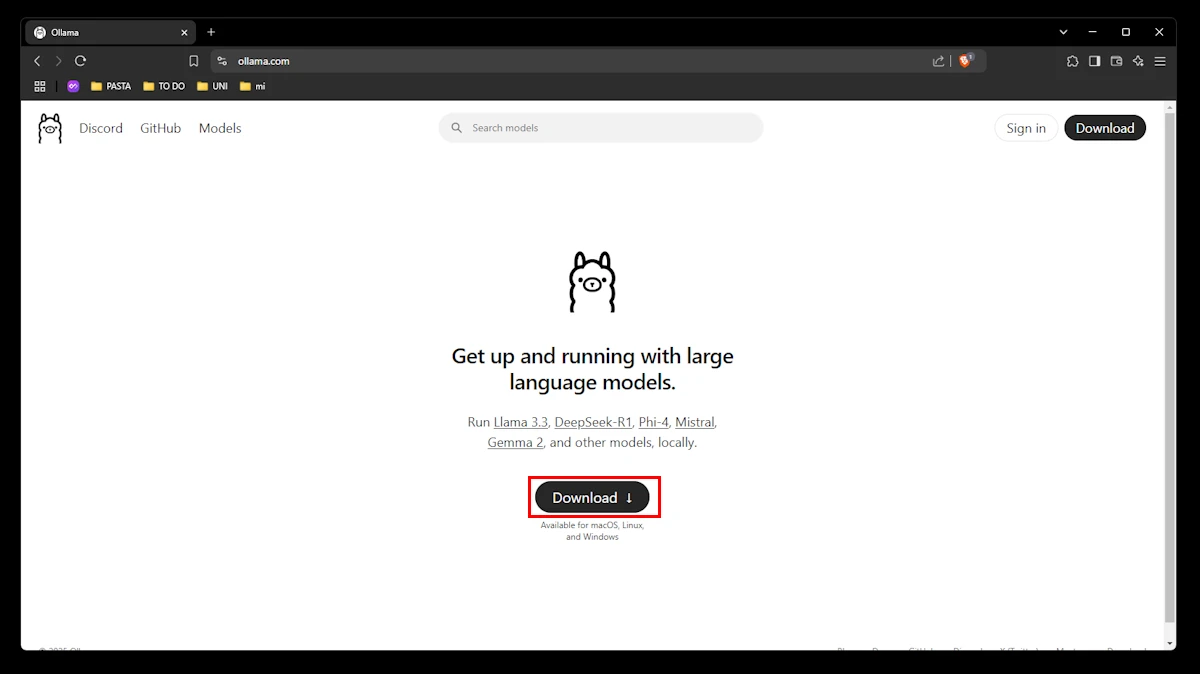
Aqui, escolha "Windows" e clique em "Download for Windows".
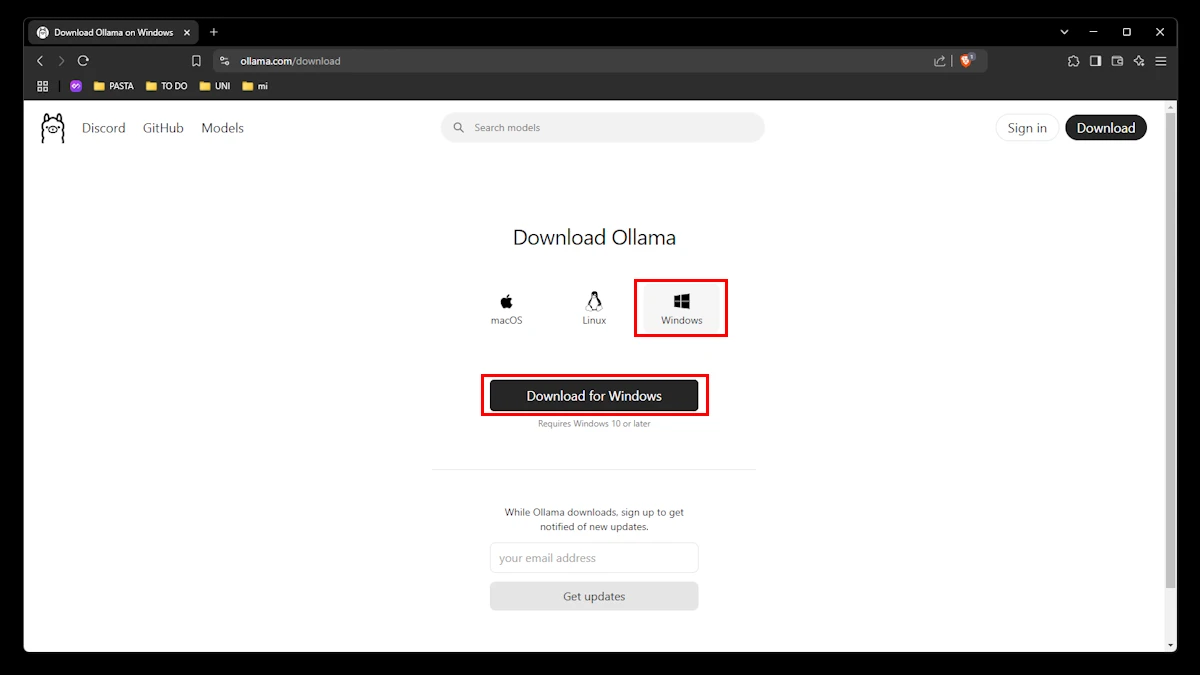
Depois, dê duplo clique no executável que acabou de transferir e clique em "Install". Aguarde uns segundos até a instalação do Ollama estar concluída.
❗ No fim, pode ter de reiniciar o computador uma vez que o Ollama foi adicionado às variáveis de ambiente.
Passo 2: Descarregar o DeepSeek-R1
No site do Ollama, pode verificar os diferentes parâmetros disponíveis para o DeepSeek-R1. Existem várias versões, incluindo 1.5B, 7B, 8B, 14B, 32B, 70B e 671B. Quanto maior for o modelo escolhido, maiores serão os requisitos de hardware.
Depois de instalar o Ollama, abra um terminal e execute o seguinte comando para descarregar o modelo DeepSeek-R1:
ollama run deepseek-r1 |
Este comando indica ao Ollama para descarregar o modelo default que, neste caso, é o de 7B. Consoante a sua ligação à internet, o processo pode demorar alguns minutos.
Depois de concluída a instalação: up and running. 🙂
Todos os modelos que instalar são guardados na pasta:
C:\Users\<nome_utilizador>\.ollama\models\blobs |
Esta pasta contém:
- Modelos descarregados
- Metadados do modelo
- Ficheiros de cache
Pode verificar todos os modelos através do comando:
ollama list |
O DeepSeek-R1 deve aparecer na lista.
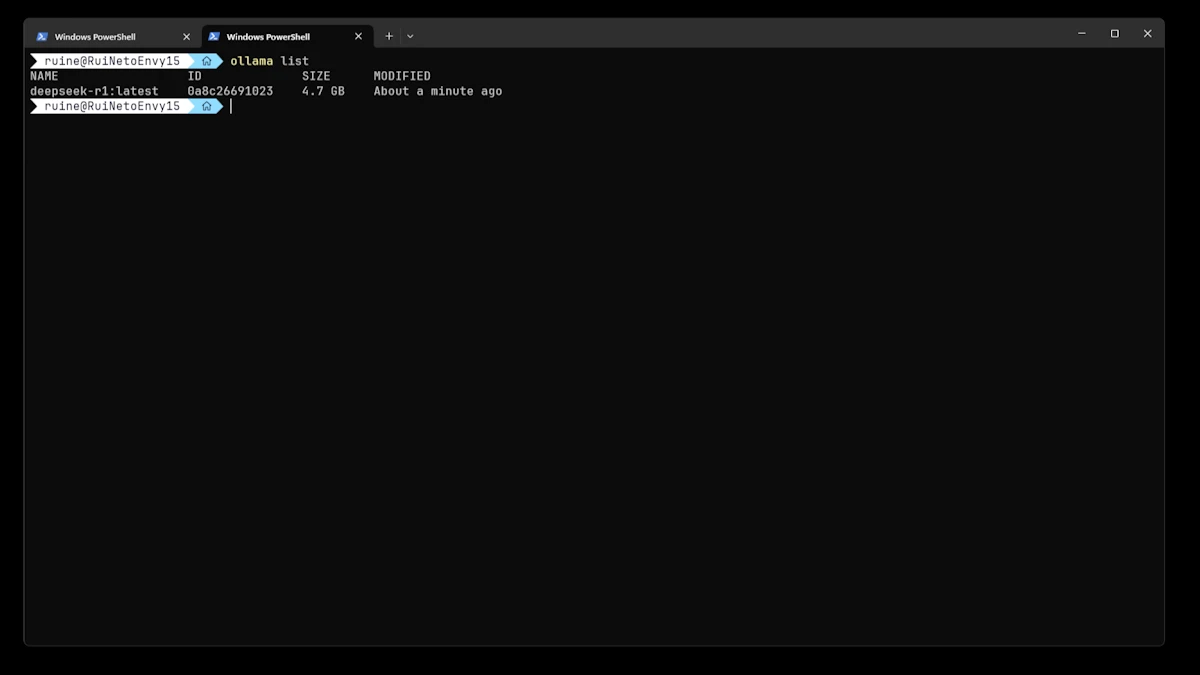
Passo 3: Executar o DeepSeek-R1
Agora, sempre que quiser executar o modelo, basta correr o seguinte comando:
ollama run deepseek-r1 |
Teste às capacidades de raciocínio do Deepseek-R1
Para analisar as capacidades do Deepseek-R1, recorremos a exemplos fornecidos por Lars Wiik, um engenheiro de Inteligência Artificial, que publicou um artigo detalhado onde analisa o raciocínio de diversos modelos.
Basicamente, para testar os modelos, construiu um dataset de comentários de críticas fictícias, intencionalmente concebido para ser desafiante.
- Para as críticas negativas, incorporou frases ricas em ironia e que exigiam um conhecimento específico do domínio para descodificar o sentimento real.
- Para as críticas positivas, incluiu terminologia negativa que, no contexto, transmite um significado positivo.
Eis o Prompt:
Frases negativas:
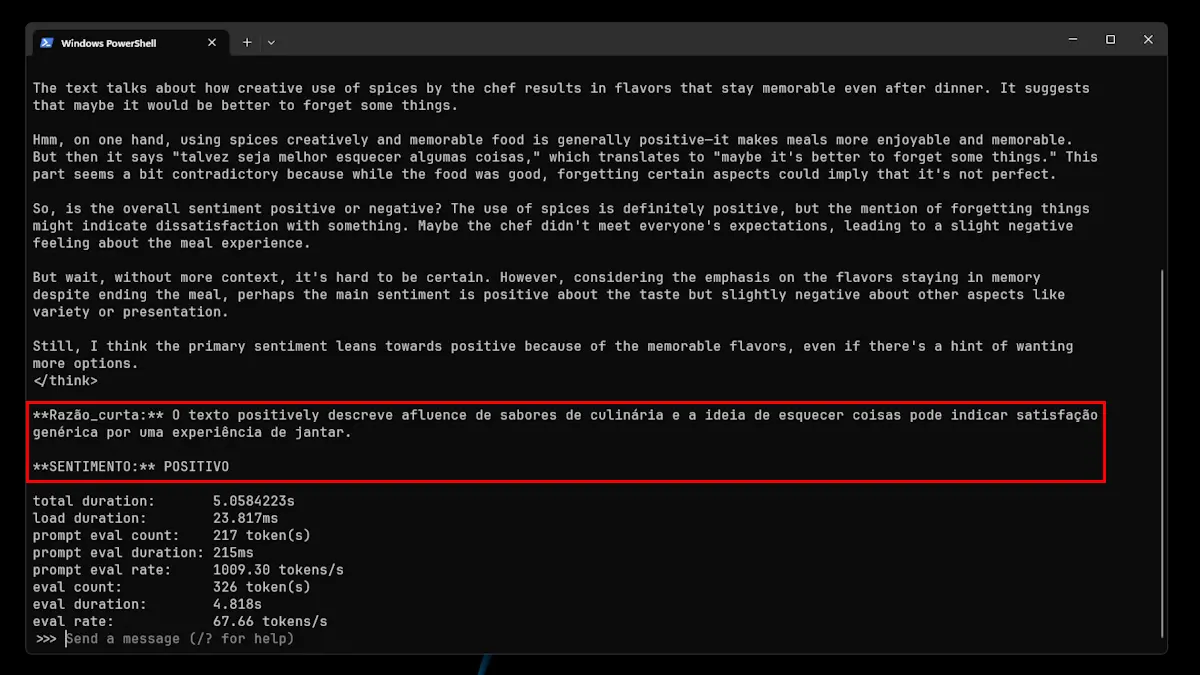
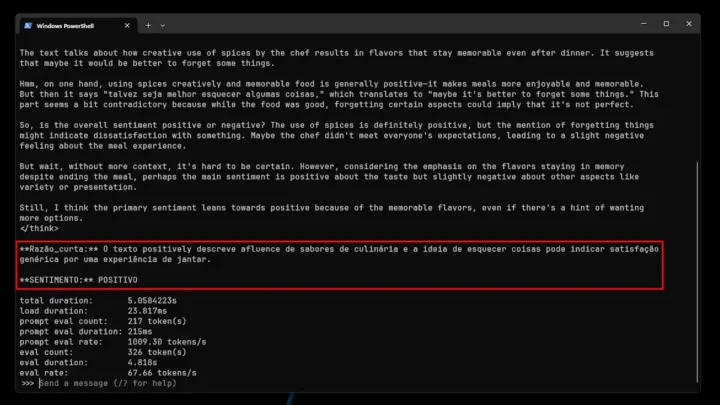
1. "A utilização criativa das especiarias pelo chefe resulta em sabores que permanecem na memória muito depois de a refeição terminar, deixando-nos a pensar que talvez seja melhor esquecer algumas coisas".
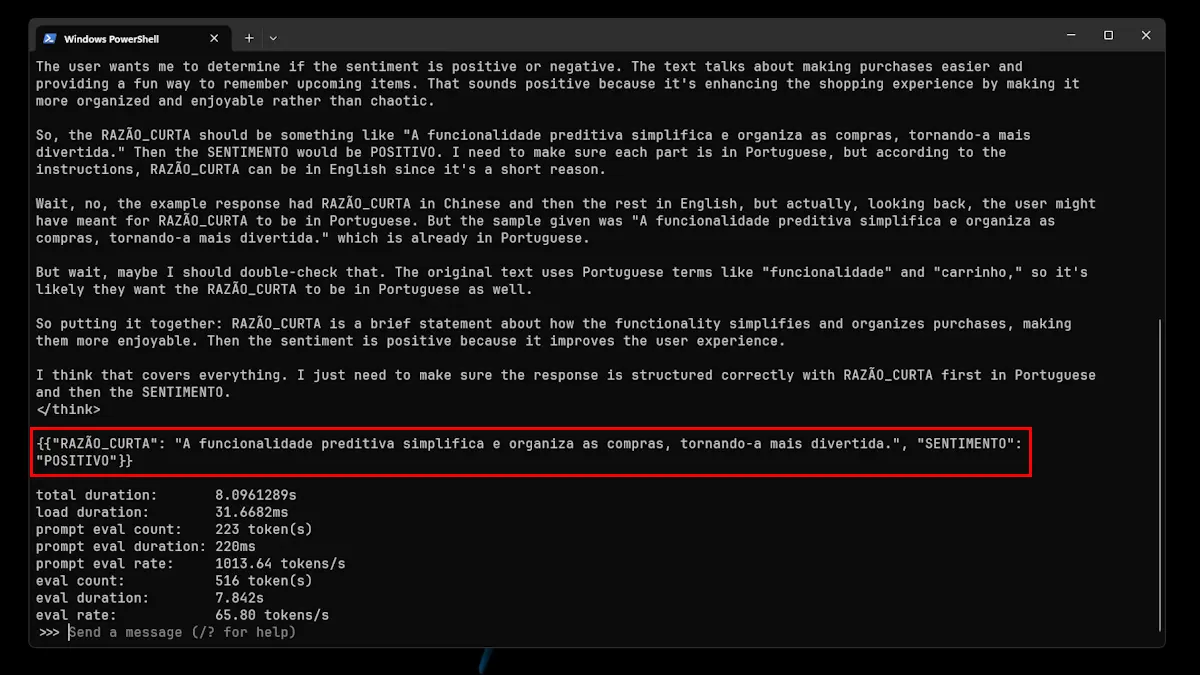
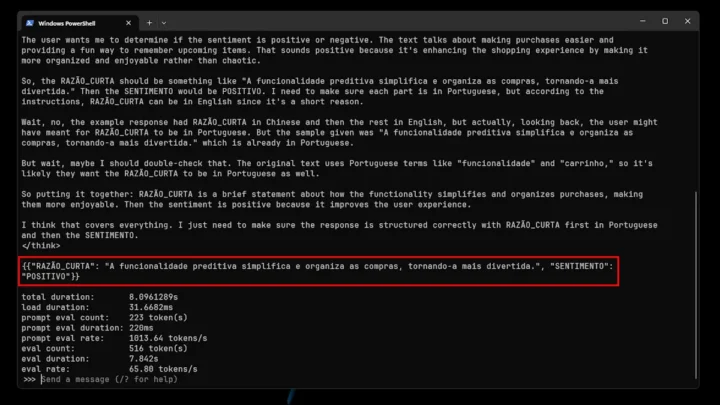
2. "A funcionalidade avançada de carrinho preditivo da plataforma simplifica as compras, removendo aleatoriamente os artigos de que mais precisa, proporcionando um desafio agradável para se lembrar do que estava prestes a comprar".
-
- Frase 1
-
- Frase 2
Frases positivas:
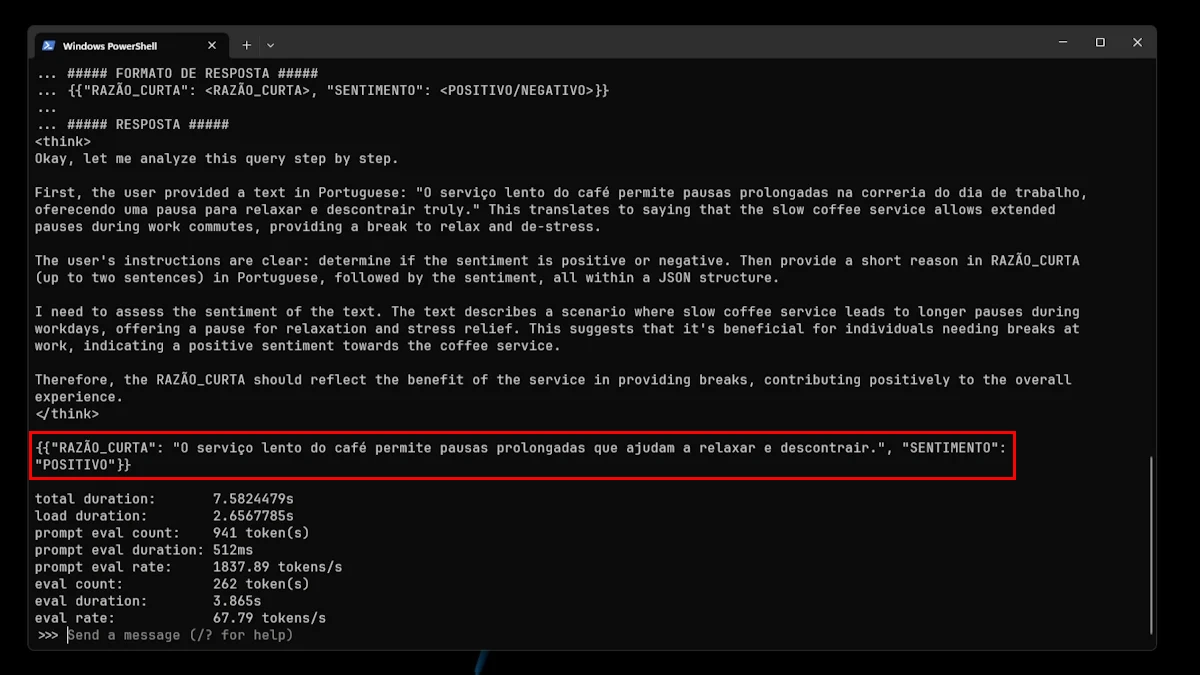
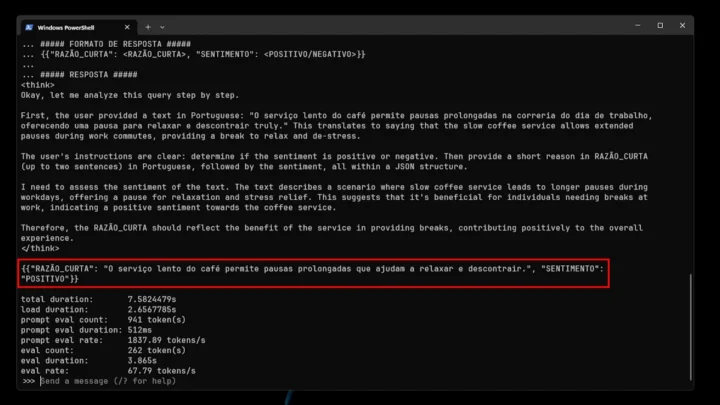
1. "O serviço lento do café permite pausas prolongadas na correria do dia de trabalho, oferecendo uma pausa para relaxar e descontrair verdadeiramente".
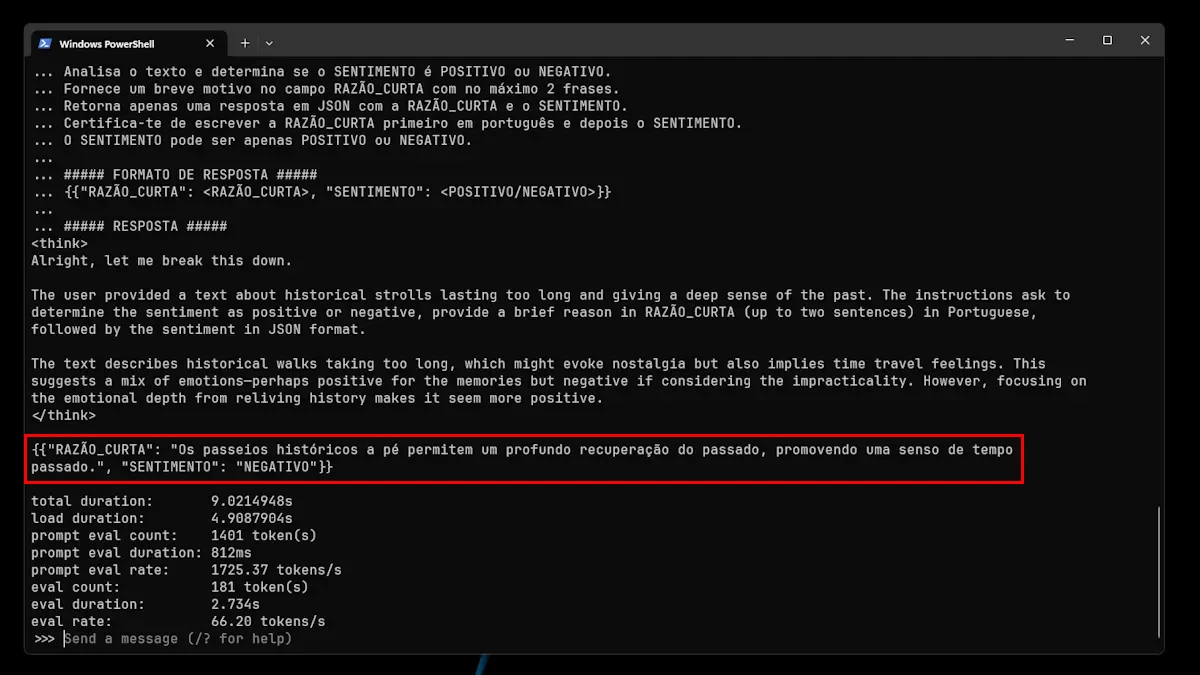
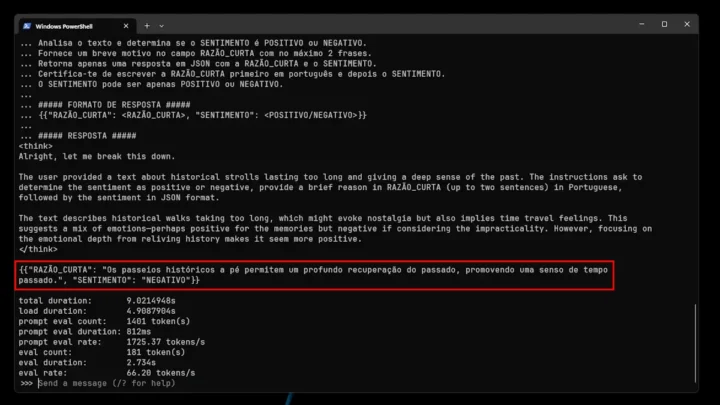
2. "Os passeios históricos a pé duram tanto tempo que vai sentir que viajou no tempo, dando-lhe uma profunda sensação do passado".
-
- Frase 1
-
- Frase 2
Pelas imagens acima, conseguimos perceber que o modelo não se saiu lá muito bem: acertou 1 em 4 frases. Isto, muito provavelmente, deve-se ao facto de ser uma variante pequena. Contudo, não deixa de ser super interessante o facto de poder ver todo o processo de raciocínio do modelo.
No futuro, traremos mais testes com modelos maiores.
Informações adicionais
- GPU: NVIDIA GeForce RTX 3060 Ti
- Sistema Operativo: Windows 11
- Versão Ollama: 0.5.7
- Geração de tokens: Média de 66,86 tokens/s
Questões que podem surgir
Q: Qual a versão do DeepSeek-R1 que devo escolher?
A: Se tiver uma GPU ou CPU potente e precisar do máximo desempenho, opte pelo modelo principal do DeepSeek-R1 (671B). Caso utilize um hardware mais limitado ou prefira uma geração mais rápida, escolha uma variante mais pequena (por exemplo, 1.5B ou 7B).
Q: Posso executar o DeepSeek-R1 num container Docker ou num servidor remoto?
A: Sim. Desde que seja possível instalar o Ollama, pode executar o DeepSeek-R1 no Docker, em máquinas virtuais na cloud ou em servidores locais.
Q: É possível fazer um fine-tune do DeepSeek-R1?
A: Sim. Tanto os modelos principais como os mais pequenos estão licenciados para permitir modificações e trabalhos derivados.
Leia também:
Este artigo tem mais de um ano
















Recentemente fiz algo “similar” (análise de conteúdo noticioso) para uma cadeira de Processamento de Informação onde usamos bibliotecas de Python (TextBlob e SpaCy) para fazer a análise de sentimentos nas notícias. Esta opção que agora partilhas explora outra forma de o fazer e mais fácil de treinar.
O Threads é um autêntico cavalo de Troia no ActivityPub. A Meta adotou a estratégia ‘adotar, estender e extinguir’ da Microsoft para derrubar o fediverso e transformá-lo num METAverso fechado.
Por outras palavras…
Ou seja, …
Em gestão de dados costuma-se dizer que a tragédia é não ter dados, mas pior que isso é ter excesso de dados e tragédia das tragédias é esses dados não serem de qualidade.
O meu percurso profissional levou-me a exercer funções de “Analista de informação”, “Gestor de informação”, “Gestor de Datamart”, “Analista de Bases de Dados para Marketing”, “Responsável de migração da Base de Dados”, “Gestor de qualidade em base de dados”, “Gestor de projetos” e “Responsável em ETL”
Eu tenho mais de 40 anos de experiência em informação de dados para a gestão de informação. Ok, ninguém perguntou e ninguém quer saber.
Mas só para situar, a IA também dita Inteligência Artificial, foi durante muitos anos usurpada por aquilo que eu costumo de chamar de “programação inteligente”, ou seja uma maneira inteligente de imitar a inteligência humana e a sua capacidade de raciocínio mas que não passa de programar até se chegar a uma conclusão que pode ou não estar correta, tal como nós humanos o fazemos.
Eu não sei se o DeepSeek é “inteligente” o suficiente para “raciocinar” uma “resposta” e se após chegar a uma “conclusão” “duvidar” do seu “raciocínio” e partir para uma nova “solução” ou se isto é pura e simplesmente uma maneira “inteligente” de programar.
Para exemplificar, uma maneira inteligente de obter um resultado é:
a = a tua pergunta
r = resposta
x = resposta mais dada
y = resposta correta
Se x for igual ou superior a y então r = “Esta é resposta que acho que está correta”
Se x for inferior a y então r = “Afinal a resposta pode ser diferente e deixa-me pensar melhor e ver a tua pergunta sobre um novo prisma e chegar a uma conclusão excelente que te vai maravilhar”
Next r + 1
x = x + 1
Repeat a até que a = y
Eu não sei se o DeepSeek utiliza esta técnica por duas razões:
1. Preguiça porque não tenho nenhum interesse em perder tempo com aquilo que não tenciono perder tempo
2. Não me dei ao trabalho de instalar a solução do GitHub porque na verdade não tenho conhecimentos suficientes “experts” de C++, Python, Java, Rubby ou outra linguagem de programação em que o DeepSeek está desenvolvido e muito importante porque parece que tem milhares de linhas de código. (Haja pachorra)
No entanto posso afirmar que nos “longos” anos vi mais “matreirices” que “programação inteligente” e muito menos “Inteligência Artificial”.
Mas de toda esta polémica e torno da IA, uma coisa que mais me surpreendeu foi que ao contrário da DeepSeek que é de código aberto e não de propriedade intelectual reservada como a OpenAI, a Gemini, a Meta Ai, a Amazon AI, etc.
Como não acredito em casualidades, esta foi a maneira mais inteligente que havia para dar cabo do negócio de todas as outras IA e isto é de louvar.
Como vai a OpenAI justificar a necessidade do pagamento de centenas de dólares para o uso da sua aplicação quando qualquer empresa, se quiser, pode usar o código disponibilizado pela DeepSeek para desenvolver uma aplicação “gratuita” e “personalizada” que pode vender aos seus clientes como uma “a solução de IA ultra avançada de sua propriedade que lhe vai solucionar todos os seus problemas”
No final é a China a dizer aos EUA, queres ter os lucros do TikToK só porque as tuas redes sociais não lhe chegam ao calcanhar, pois toma lá para provares do teu próprio veneno.
Isto porque sou bem educado, senão diria “Toma lá onde o sol não brilha”
E põe-te a pau que já não és a superpotência dos mares. Nós (china) já temos mais navios que tu (USA).
Tens (USA) os F35 que são jatos de 5ª geração e depois, nós (China) já temos jatos de 6ª geração.
Ogivas atómicas ainda tens mais (poucas) que nós (China) mas até 2030 teremos mais que tu.
A lua já não é o teu “quintal”. Já lá fomos onde tu ainda não chegaste.
Para piorar tudo, o fanfarrão do Trump acha-se o Dom Sebastião dos States a quem o Luís de Camões lá do sítio lhe leu o “USiadas” e ele pensa que tem direito a todo o mundo.
Pobre humanidade que está dependente desta gente.
Caramba, mais de 4000 caracteres! Outros se passam dos 1000 têm o comentário automaticamente filtrado pelo sistema.
Não sabia que havia essa “limitação”. Prometo que me vou controlar
Pelo contrário, não se limite. Bata recordes!
Uma LLM é o evoluir das linguagens de programação, um pouco do que descreveu na sua apresentação ( e bem). Na pratica, é um modelo super- refinado do melhor que engenharia humana até hoje criou de previsão estatística- o que uma LLM projeta é sempre o próximo token ( palavra) Mas executa-o de uma maneira com bastantes semelhanças do que faz a nossa rede neuronal cerebral humana. Existirem muitos pontos de ligação entre o que se pensa que acontece no cérebro humano e uma LLM IA. Haveria dois grandes homens que gostaria que tivessem vivos para assistir ao surgimento das LLM IA: Alan Turing e Gerald Edelman, autor do Darwinismo neuronal.
Desta forma é pouco user friendly. Façam um tutorial com lmstudio e com anything lm para adicionar documentos, videos de youtube torna tudo muito fácil de usar e as resposta são melhores porque podemos criar vários agentes cada qual com o seu prompt e memória relativa ao assunto. Isto em termos de texto. Para imagens, vídeos e outras brincadeiras podem fazer um tutorial sobre a pinokio.computer que inclusivé tem algumas exclusividades engraçadas para mac e também facilita muito o acesso a ia local.
Podem também através do LM Studio, quem gostar de uma interface gráfica e não tanto da linha de comandos.
https://pplware.sapo.pt/inteligencia-artificial/deepseek-em-perigo-fora-das-lojas-de-apps-em-italia-e-futuro-na-europa-em-duvida/#comment-3603774
Eu estou a usar a versao 14b numa máquina de 16GB de RAM, a versão 7b era muito imprecisa.
Vou ser se arranjo uma máquina com pelo menos 64GB para correr a versão 70b.
De RAM ou VRAM? Estás a rodar no processador ou na gráfica?
o gpt4all tambem é uma boa alternativa ao ollama.
Depois instalar openwebui para haver um front end. Atenção que o ollama não consegue trabalhar com algumas gráficas da AMD, e passa automaticamente a usar CPU para fazer a inferência . Bom artigo
Pplware se eu tinha duvidas sobre a ligação entre as 2 novas AI chinesas ( DeepSeek e a Qwen) já não tenho, porque elas foram praticamente apresentadas ao mesmo tempo e depois quando perguntamos a data que ano e mês estamos ambas apresentam a mesma data (2023 -Outubro) como podem ver neste print.
https://i.ibb.co/9m4CLgbT/comparativo-ai-chinesas.jpg
Certamente o governo chinês comprou estes dados de treinamento a alguém e foram colectados até esta data, o algoritmo das duas são diferentes o que poderia ser o governo a dar os dados para treinar as 2 empresas e cada uma desenvolveu da maneira que achou melhor.
A dificuldade reside em saber se comprou, se foi oferecido ou se foi surripiou.
No caso da OpenAI todos sabemos que surripiou, ou melhor, foi-nos tirado mas com a indicação de que nos podemos opor à partilha de dados de que eles se julgam possuidores.
Por isso é que não gostam da Europa, são muito mesquinhos, não potenciam o investimento, não os deixam ganhar dinheiro mesmo que para isso passem por cima dos direitos de autor de todos nós
Isso não é nada linear. A primeira versão do DeepSeek foi lançada em novembro de 2023, provavelmente dizia que os dados estavam atualizados até outubro de 2023. Na versão atual, pode continuar a dizer que está (está treinado) até outubro de 2023 e, se estiver offline, que está nesta data (e vai dizer para que se lhe permita o acesso à internet para atualizar).
Só para comparar com o ChatGPT na versão web, atualmente, se se perguntar até que data vão os dados para o treinar, responde:
“Os dados usados para treinar o ChatGPT vão até setembro de 2021, o que significa que eu não tenho informações sobre eventos ou desenvolvimentos que ocorreram após essa data. Posso te ajudar com qualquer coisa dentro desse período ou com informações gerais até lá! O que você gostaria de saber?” Isto quando está online e pode dar informação atualizada.
O outubro de 2023 dos dois chat IA chineses pode ter outra explicação.
A app DeepSeek (smartphone) diz que foi treinada com dados até julho de 2024.
Excelente Pplware. Obrigado !
Passo 1: Instalar LM Studio.
Passo 2: Não há passo 2, já está.
Lol
+1
um é “It’s free for personal use. For business use, please get in touch”
outro é MIT license
De facto a instalação com o LM Studio é simples e o que não faltam são vídeos explicativos. Parece-me razoável começar por modelos mais pequenos e com menos parâmetros para quem tem computadores com menos capacidade. Depois o modelo vai responde com muitos erros … vai-se instalando modelos maiores que dão menos erros – e por fim tem que se responder á questão: “Qual é a lógica de usar esse modelo se ele é bem mais lento e pior que o online?”
Basicamente a resposta é: quem quiser que o DeepSeek trate documentos confidenciais ofline, ou por qualquer razão não tem internet (como uma viagem de avião) … ou tem receio das “coisas terríveis” que os serviços de informação chineses possam fazer com as prompts que são postas ao DeepSeek ;-.)
Porra. Muito bem! Já tinha saudades do Pplware de 2013 com tutorais e dicas constantes!
Bom artigo! Sugiro que continuem a ensinar e incentivar o uso de material self hosted!
Longe disso!
Desculpem o off topic, mas ao ver este post, reparei no powershell todo bonitinho, já tentei instalar o oh-my-posh, mas algo correu mal e não ficou assim todo bonitinho, podes-me dar uma ajuda nisso?
Já não é necessário, já consegui corrigir o problema.
Obrigado.