

 Proponha uma correção, faça uma sugestão
Proponha uma correção, faça uma sugestão



Dica: 9 formas de melhorar as respostas do ChatGPT e qualquer outro chatbot
A qualidade das respostas do ChatGPT depende significativamente da formulação do seu prompt. Algumas variações ou adições podem enriquecer a informação obtida. Portanto, deixamos 9 formas de melhorar as respostas do seu chatbot do dia a dia.

Embora focado no ChatGPT, estas dicas podem ser igualmente aplicadas a outros chatbots de inteligência artificial (IA) como o Claude, o Gemini, o Grok, entre outros.
1. Falar com o ChatGPT é diferente de falar com um motor de pesquisa
O ChatGPT processa o texto de forma distinta de um motor de pesquisa, sendo treinado para interpretar linguagem natural. Não use palavras-chave isoladas; em vez disso, formule a pergunta de forma natural, como faria ao pedir ajuda a uma pessoa.
Em vez de:
sort function golang
Diga:
Quero ordenar uma lista de números inteiros de forma crescente. Podes mostrar um exemplo prático de como usar a função "sort" na biblioteca padrão de Go? Além disso, há algo específico que devo saber sobre como o sort lida com slices em Go?
2. Diga o que quer, não o que não quer
Para obter melhores respostas, é crucial ser claro e detalhado ao formular a pergunta. Considere o contexto e especifique exatamente o que quer. Por exemplo, ao solicitar um texto para um e-mail, detalhe o idioma, o propósito (como uma candidatura de emprego), e o tom profissional desejado. Priorize o "Quero um tom profissional" antes do "Não quero um tom amador".
3. Detalhes importam, muito
Não economize em detalhes ao solicitar ajuda ao ChatGPT, seja para compor uma imagem, onde cada detalhe conta, ou ao gerar um texto, onde especificar o público-alvo e o formato desejado enriquece a resposta. Evite ambiguidades e generalize o menos possível.
4. Especifique a estrutura desejada
Quando solicitar ao ChatGPT a composição de um texto, especifique a estrutura desejada. Se precisa de uma comparação entre dois produtos, mencione se deseja "uma lista de prós e contras" ou "uma análise aprofundada".
5. Adapte as explicações do ChatGPT ao seu nível de compreensão
Se precisar de explicações sobre um tema complexo, peça ao ChatGPT para simplificar a linguagem. Por exemplo, pode pedir que explique como se estivesse a explicar a uma criança de 10 anos, e ele adaptará a terminologia e os exemplos para facilitar a compreensão.
6. Especifique as fontes desejadas
Para obter informações precisas, especifique as fontes desejadas ao ChatGPT. Por exemplo, peça que baseie a explicação em estudos académicos válidos, garantindo assim maior fiabilidade na informação fornecida.
7. Mencione instituições ou meios específicos
Além de tipos genéricos de fontes, pode solicitar ao ChatGPT que utilize fontes específicas como instituições, páginas web ou autores reconhecidos.
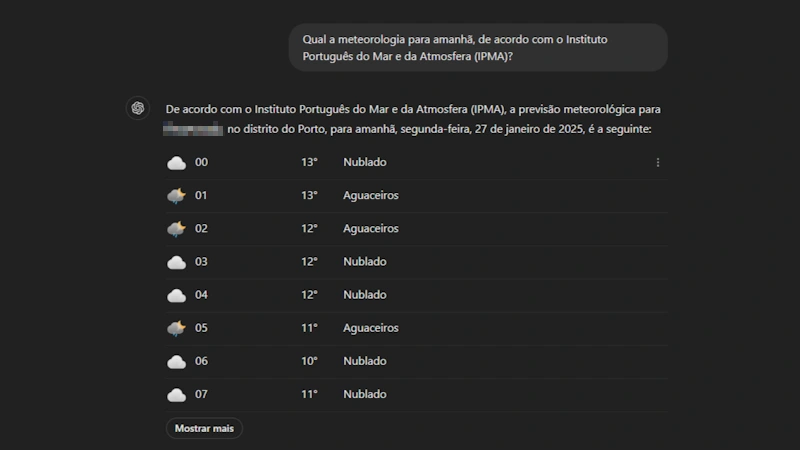
8. Solicite informações atualizadas
Se precisar de informações recentes, especifique ao ChatGPT que forneça dados atualizados, como "dos últimos 2 anos". Isso é crucial para obter informações precisas e relevantes à sua consulta.
9. Peça ao ChatGPT citações das fontes
Para maior credibilidade, peça que inclua citações das fontes utilizadas na resposta. Por exemplo, ao solicitar uma explicação sobre um tema específico, pode pedir que cite estudos ou pesquisas relevantes. Ele adicionará os nomes das fontes, assim como um link para aceder diretamente a elas. Por vezes, ele pode citar fontes inválidas, ou que já não se encontram disponíveis. Por isso:
Verifique sempre a informação
Embora os chatbots como o ChatGPT sejam poderosos, podem ocasionalmente fornecer informações incorretas. Verifique sempre as informações obtidas com outras fontes confiáveis para garantir precisão.
Além disso, para garantir que o seu texto está livre de erros, pode ser utilizado um corretor ortográfico, ajudando a melhorar a clareza e o profissionalismo das respostas geradas.
Seguindo estas orientações, poderá maximizar a utilidade do ChatGPT e de outros chatbots, garantindo respostas mais precisas tendo em conta as suas necessidades específicas. Se quiser ir mais além, deixamos o guia completo da OpenAI:
Leia também:
Este artigo tem mais de um ano















ChatGPT já foi ultrapassado. DeepSeek é open source. Com um investimento de 5 milhões, o projeto paralelo de uma startup chinesa derrotou toda a indústria tecnológica americana, provocou uma queda nas bolsas mundiais e chegou ao 1º lugar na App Store americana. A China venceu, é 95% mais barato! Todos os “líderes” da IA ganham mais do que 5 milhões, não existem mais razões para os custos de milhares de bilhões. O Projeto Stargate está morto. Este é o momento Sputnik na corrida para a AGI, o cisne cinza chegou.
Mesmo desacelerando, bastante, relativamente ao que dizes, não há dúvida que a DeepSeek é um projeto muito interessante. Destaco:
“Ao contrário de muitas empresas chinesas de IA que dependem muito do acesso a hardware avançado, a DeepSeek concentrou-se em maximizar a otimização de recursos orientada por software”.
“De acordo com Liang [Wenfeng, o fundador] quando ele montou a equipe de pesquisa da DeepSeek, não estava à procura de engenheiros experientes para construir um produto voltado para o consumidor. Em vez disso, concentrou-se em estudantes de doutoramento das principais universidades da China, incluindo as Universidades de Pequim e de Tsinghua, que estavam ansiosos para provar a si mesmos”.
https://www.wired.com/story/deepseek-china-model-ai/
De facto a IA DeepSeek provocou uma tremenda queda nas ações da Nvidia nesta 2ª Fª:
– As ações da NVIDIA caíram mais de 15%, mais de 500 mil milhões de dólares.
– NVIDIA, TSMC e ASML entre os stocks ameaçados pela DeepSeek
Isto percebe-se – se a IA estava a ser desenvolvida com suporte em investimentos massivos em hardware, e agora surge uma forma de ser suportada em software, com hardware reduzido, os fabricantes de hardware levam um valente tombo.
Não Mestre Aves. Tem a ver com eficiência:
MoE
MLA
FP8
MTP
Caching,
e sobretudo o preço da energia barato na China, e custos mais baixos de tudo no seu geral. Treinamento e bases dados foram buscar em tudo o que conseguiram mais pelo treinamento dos modelos que estão em vigor ( OPENAI, LLAMA, ANTROPIC, outros). O hardware tem de lá estar na mesma (senão não conseguias servir milhares de pessoas ao mesmo tempo) apesar das restrições impostas pelos USA, eles lá conseguiram meter mãos nalguns milhares de H100 da Nvidia e também da AMD. A deepseek é boa, muito boa para opensource, mas não é melhor que o modelo de topo da openai. O que é, é muito mais barato. Eu também uso. Queres respostas / progamação boas, tenta obter pelo menos de 3 modelos diferentes. Sempre podes tu fazer um MOE no openweblm de várias IAs – metes 10 paus na API do openrouter e fazes a festa pra 2 meses ou mais.
2.800 gráficas H800, modelo desenvolvido pela Nvidia para o mercado chinês e que não está sujeito ao embargo (têm uma capacidade de processamento inferior à A100, sujeita a embargo). É o que a DeepSeek diz que precisou para treinar o modelo, em 53 dias.
Mas o ponto é que a DeepSeek anunciou que o treino do seu algoritmo custou menos de 6 milhões de dólares (para arredondar, 5 milhões de dólares) que compara com o custo de 5 mil milhões de dólares) do modelo da OpenAI e segue-se ao anúncio de Trump e Sam Altman, de um investimento de 500 mil milhões de dólares para desenvolvimento da IA. Há aqui uma mensagem clara da China, que consegue o mesmo com muito menos, que não se trata de uma questão de dinheiro.
Há bastante tempo que nos EUA andam nervosos com o que a China é capaz de fazer com hardware mais barato e que não está sujeito a embargo. Pela queda do valor das ações da Nvidia e de outros fabricantes de hardware, o susto agora foi dos grandes.
Sim, mas também têm uns milhares de H100. Não é treino de algoritmo, é só treino, alinhamento, os weights e aplicaram as técnicas que te referi. As LLms não têm algoritmo, isso é nas redes sociais. 2.800 gráficas H800 isso não é nada Mestre. Quanto ao projeto do orange men, não faço verdadeira ideia do que eles querem fazer, não se percebe lá assim muito bem. Bem , o que eles anunciam o que gastaram na deepseek não sei se corresponde á realidade, afinal estamos a falar da CCP da china…mas o modelo é bom, bem classificado nos benchmarks ( não é o melhor) mais leve, mais rápida a treinar por ter tido menos intervenção humana no seu ajuste ( alinhamento), usar o MOA foi inteligente, pois só usas as partes que interessam na tua questão especifica, entre as outras técnicas referidas. É OPENSOURCE, se tiveres máquina (quase ninguém tem) podes ter em casa com toda a privacidade adjacente. Nada disto foi original em termos de IA, mas o que a china faz e muito bem é agarrar no que existe de bom e fazer um bom produto , a um preço imbatível. Pessoal em pânico vendeu shares da Nvidia e ainda bem, já comprei na queda e já subiu outra vez, mais um bocadinho acima do que eu quero e vendo outra vez. Não sei como estás de material mas já vi que gostas, se tiveres pelo menos uma gtx4080 podes baixar uma nova que saiu ontem multimodal, a qwen VL 25, com 72B, muito, muito boa nos benchmarks e podes ter em casa com toda a privacidade, sem espiões ou roubo de dados.
Ninguém mais diz que têm ou usaram A100, mas tu bates o pé. Quanto ao algoritmo, o treino de um modelo tem que ter por base um algoritmo, inspirado no cérebro humano (redes neurais). Sim, os chineses da DeepSeeko desenvolveram o seu.
São os weights e o alinhamento é definem o seu comportamento. O seu treinamento e as bases de dados de treinamento. Não é algoritmo nenhum. Rede neuronal sim, muita algebra e vetorização. Não se fazem omeletes sem ovos, o que li é que conseguiram por as mãos nalgumas H100, e complementam com as h800 e tudo o mais que lhe consigam deitar a mão. As H100 foi o que li já em vários sítios, não critico, eu teria feito exatamente o mesmo. Eu gosto da deepseek, deu um abanão, quantos mais abanões dão, mais o consumidor recebe. Foi o Ceo da Nvidia que o disse das H100, não fui eu. Aqui: https://www.reddit.com/r/NVDA_Stock/comments/1i9wkg1/chinese_ai_lab_deepseek_has_50000_nvidia_h100_ai/
E não utilizaram nada e novo mundo da IA: usaram os métodos que te indiquei . Fizeram um excelente produto final com estas técnicas: MoE, MLA, FP8, MTP, Caching- são formas eficientes de inferência e treinamento- Não te estou a criticar, estou a informar-te, e tens bom gosto mestre Aves.
Não foi o CEO da Nvidia que disse que a DeepSeek tinha 50.000 NVIDIA H100. Foi o CEO da Scale AI, Alexandr Wang, acrescentando que a DeepSeek tinha mas não podia confirmar.
Vê o antepenúltimo parágrafo.
Está lá a confirmação do wang. Se conseguiram algumas h100 fora do embargo foram espertos, nada a criticar. Ainda hoje fartei-me de usar o deepseek. Está mais rápida hoje. E graças a eles isto está bem lançado, a openai vai ser obrigada a baixar os preços das API. Mais dois modelos novos da qwen nas últimas 24 horas muito bons também. A seguir o grok 3 já anunciado pra esta semana e a meta dou-lhe duas semanas. Mês de janeiro quente quente
Wang (americano) não confirma nada, o que ele disse foi:
“Os laboratórios chineses têm mais H100s do que as pessoas pensam”, disse Alexandr Wang, um empreendedor americano de IA, numa entrevista à CNBC. Wang disse que acreditava que a DeepSeek tinha um stock de chips avançados que não havia divulgado publicamente por causa das sanções dos EUA. ”
Quem agora não tem autorização para comprar (o que não é o mesmo que estar proibido de comprar, como a Rússia e a China) as A100, são, por exemplo, Israel e Portugal.
Pois é, este wang não é o da Nvidia não. Outra coisa que já se descobriu e aqui a inovação é quase exclusivamente da equipa deepseek foi a forma de rentabilizar o firmware das GPU da Nvidia, usando um ” hack ” para usar algo diferente que não “CUIDA ” Desta forma abre portas a novos drivers / mods alternativos pro resto da malta toda ( eventualmente): https://www.tomshardware.com/tech-industry/artificial-intelligence/deepseeks-ai-breakthrough-bypasses-industry-standard-cuda-uses-assembly-like-ptx-programming-instead
De qualquer modo, se a DeepSeek tivesse 50.000 A100 não era nada. Zuckerberg tem 600.00 e quer chegar ao fim do ano com 1 milhão.
Entretanto, países como Portugal podem não ser autorizados a comprar nenhuma
Por isso, o hardware utilizado para treinar o modelo foi o que mais chamou a atenção.
exatamente! Assim abre um novo paradigma de reduzir muito mais os gastos com energia no planeta com a IA
A adaptação ao método do deepseek já começou hehehe! Não adaptar as GPUS como a china fez é deitar energia literalmente ao lixo: olha ai os gajos da Perplexity: https://openrouter.ai/perplexity/sonar-reasoning
Qual ]e o stock disso?
PCCh
Excelente artigo. A questão inicial e as questões de follow-up são muito importantes. Eu costumo dizer que o modelo de IA pode ser tanto melhor ou pior proporcionalmente á inteligência biológica que está á frente dela. Deepseek, gpt4, qwen 2.5, bard, PHI 4, llama 3.3 , todas elas boas, incluindo as que se podem rodar em casa aos afortunados do hardware. Vai ficar melhor ainda. Próximo ano a robótica vai começar a surgir mais.
O ponto 5 foi pensado para ser utilizado pelos políticos.
Ja sao 18h.. tambem ja esperava um artigo do pplware sobre a deepseek, sei que ja falaram em dezembro, mas o interesse e o impacto no mundo está a ser agora.