 Proponha uma correção, faça uma sugestão
Proponha uma correção, faça uma sugestão



OpenAI gastou US$ 78 milhões para fazer o mesmo que a Alibaba fez por US$ 500 mil
A corrida pela supremacia na inteligência artificial (IA) não se mede apenas pela potência, mas cada vez mais pela eficiência. A Alibaba acaba de demonstrar que é possível treinar modelos de topo com uma fração do custo dos seus concorrentes, como a OpenAI.

A nova era de eficiência da Alibaba
A Alibaba Cloud, o braço de infraestrutura na nuvem da gigante tecnológica chinesa, surpreendeu o mercado ao apresentar a sua nova família de Large Language Models (LLM), a Qwen3-Next. Descritos pela empresa como "o futuro dos LLMs eficientes", estes modelos representam um salto quântico em termos de otimização de recursos.
Para se ter uma ideia, são 13 vezes mais pequenos que o modelo mais robusto que a própria empresa havia lançado apenas uma semana antes.
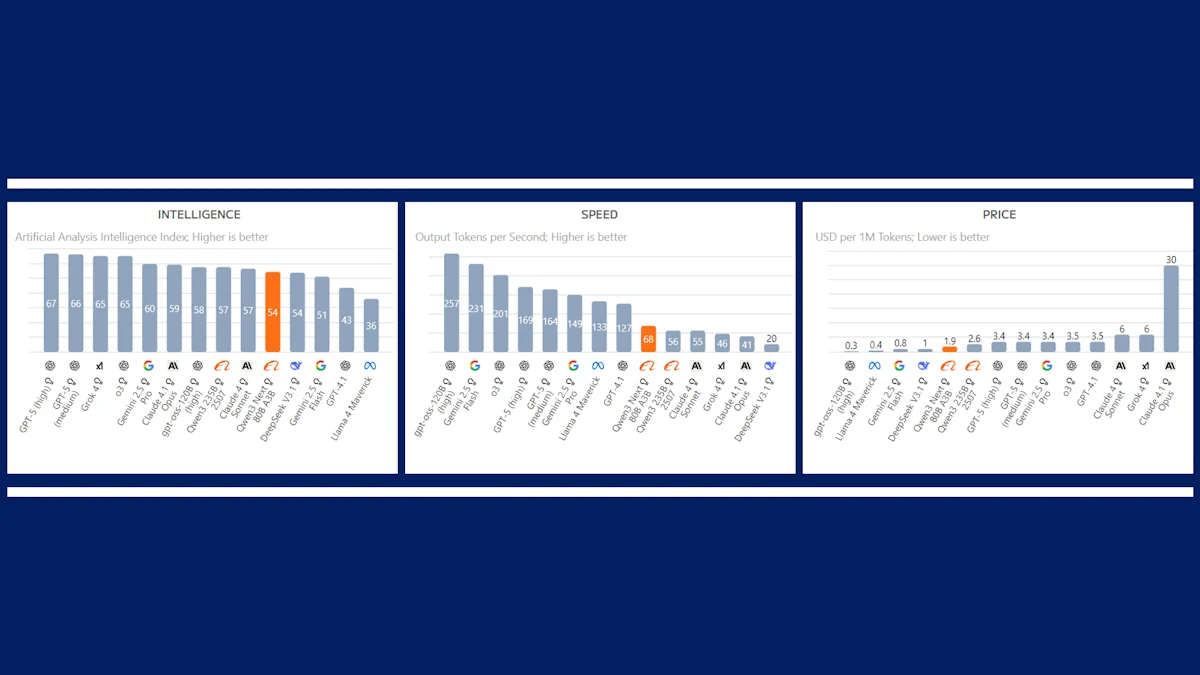
Dentro desta nova família, o destaque vai para o Qwen3-Next-80B-A3B. Segundo os seus criadores, este modelo não só é até 10 vezes mais rápido que o seu antecessor, o Qwen3-32B, como também atinge esta performance com uma redução impressionante de 90% nos custos associados ao treino.
Para contextualizar a magnitude desta conquista, basta olhar para os custos da concorrência. De acordo com o AI Index Report da Universidade de Stanford, o treino do GPT-4 custou à OpenAI cerca de 78 milhões de dólares em poder computacional. A Google investiu ainda mais no Gemini Ultra, com um valor estimado de 191 milhões de dólares.
Em contraste, estima-se que o treino do Qwen3-Next terá custado apenas 500.000 dólares. Embora a Alibaba não tenha confirmado valores exatos, o seu artigo oficial revela que o Qwen3-Next-80B-A3B utilizou "apenas 9,3% do custo computacional (horas de GPU)" do modelo anterior, o Qwen3-32B.
Qual é o segredo para tamanha eficiência?
Os modelos Qwen3-Next utilizam a arquitetura Mixture of Experts (MoE), que divide o modelo em várias sub-redes neuronais especializadas, conhecidas como "especialistas".
A Alibaba elevou esta abordagem a um novo patamar, utilizando 512 especialistas - um número superior aos 256 do DeepSeek-V3 ou aos 384 do Kimi-K2 - mas mantendo apenas 10 ativos em simultâneo, otimizando drasticamente o processo.
O segundo pilar desta eficiência é uma técnica de "atenção híbrida" chamada Gated DeltaNet, desenvolvida em colaboração pelo MIT e pela NVIDIA. Esta tecnologia refina a forma como o modelo processa a informação de entrada, determinando de forma inteligente que dados são cruciais e quais podem ser descartados.
O resultado é um mecanismo de atenção preciso e extremamente económico em termos de recursos computacionais.
Apesar do seu baixo custo de treino, o desempenho do Qwen3-Next-80B-A3B é notável. Em testes de desempenho realizados pela Artificial Analysis, o modelo da Alibaba superou concorrentes diretos como o DeepSeek R1 e o Kimi-K2. Embora não destrua os gigantes do mercado como o GPT-4, o seu rendimento é excecional quando se considera o investimento necessário.
Este lançamento reflete uma tendência crescente na indústria: a procura por modelos mais pequenos, especializados e eficientes. A Alibaba prova agora que é possível alcançar um desempenho de topo sem necessitar de um orçamento multimilionário.
Leia também:

















Tenho testado este modelo Qwen3 Next 80B localmente e tal como outros MoE a experiencia nem sempre é a melhor. Dá ideia que por vezes a escolha do “expert” acerta ao lado. No entanto é muito rápido como seria de esperar com esta técnica.
Mas porque raio andas a testar llms localmente? Podes fazê-lo por meia dúzia de euros em qualquer public cloud
Tenho acesso a servidores com 512gb ram num data center que giro. Basicamente posso, tenho recursos testei… É isso
que importa RAM e CPU, corres isso em 1/100 do tempo com determinados GPUs em cloud publica
Pra ter offline em casa. Mas como fazes, dá ai uma dica ao pessoal. É através de API? Como fazes o loading do modelo? Parece interessante
Neste caso como não há “quantization” usei um servidor com 96 cores/512GB RAM, e tenho ideia que consegui 10 tokens/s +/-. Para os meus testes chegou e sobrou. Praticamente só fiz questões de lógica, raciocino, matemática, programação, numa ótica de comparação com outros modelos. E fui fazendo literalmente em paralelo com o meu trabalho. Enviava as prompts e passado algum tempo ia ver os resultados. Não foi rápido, também não foi lento.
Deixa-me que te diga que com GPUs não conseguia 100 vezes mais velocidade, mas acredito que umas 20 vezes mais rápido seria sem dúvida.
Se eu quiser algo mais a sério ou complexo, tenho outros meios com GPU, mas que de momento estavam “ocupados” e/ou os que havia não tinham VRAM para este modelo não “quantizado”.
Como disse para os meus testes rápidos chegou e sobrou e não tive necessidade de utilizar nada mais rápido.
Tendo acesso aos recursos que tenho, não me faz sentido subscrever clouds. Mas se precisar de “processar” algo complexo e /ou tiver pressa claro que nessa altura é uma opção.
Eu no dia a dia nunca iria utilizar um modelo assim não “quantizado” fp16. É estupidamente demasiado pesado em termos de recursos, para pouco retorno.
No dia a dia para coisas a sério uso máquinas com GPU e quantização Q8 ou Q6_K dependendo do modelo LLM e lá está, não preciso de subscrever nada e tenho respostas na casa dos 50 a 100 tokens/s. Que é mais do que suficiente para mim.
De qualquer forma obrigado pela preocupação, claro.
Boa. Em casa, modelos que consiga correr F16 só mesmo os pequenos. Os outros, alguns com offloading e de preferência unsloth Q6K-xl UD ou até eventualmente Q5 do mesmo. Ou bartowski. Agora o que o Fonseca estava a dizer também parece interessante, alugar uma gpu online. Só não estou a ver como se faz todo o processo
A forma mais fácil e usares Cloud Run, quase não precisas de saber código, há aí uns cursos de meia dúzia de horas para te ajudarem a correres modelos desses em menos de 1-2h, temos aqui uns miúdos a brincar nuns labs com isso e a dar grande show com ideias muito boas e muito pouco esforço.
Se for uma coisa mais a sério sugiro GKE, é o que estamos a fazer aqui, temos tudo em cima de kubernetes, facilmente pegamos e mandamos isso para outro cloud provider ou para on prem, onde der mais jeito correr ou tiver menor custo, andamos a fazer uns testes com local GPUs para cenas OT e está a correr muito bem com pouco investimento
Hugo Nabais, és um homem de sorte por conseguires rodar o full model. Ainda estou á espera do suporte para llamacpp, para as GGUFs, que pelos vistos vai demorar semanas ou meses, devido á arquitectura ser algo radicalmente novo. Testaste também o modelo Qwen3 Next 80B VERSÃO ThinK ? Pelo Openrouter consigo os melhores resultados. Até para rodar no portátil o modelo anterior Qwen3-30B-A3B-Thinking-2507, já por si é acima da média, na minha opinião superior ao gpt-4o de março deste ano.
A versão Think não testei, mas testei o Qwen3-30B-A3B-Instruct-2507 (quantized) e gostei muito dos resultados dos testes! Eu diria que é quase tão bom como o Qwen3 Next 80B A3B! Ligeiramente abaixo mas por muito pouco, nos testes que fiz.
E tendo em conta que é muito mais leve eu diria que é uma boa aposta agora. Se tiveres oportunidade experimenta.
Tenho pena de não ser “pensante” por um lado, por outro é mais direto nas respostas. Mas tenho que ver se testo a versão Think.
Agora é que li melhor o teu post, e sim o Qwen3-30B-A3B-Thinking-2507 é excelente, já vi que já testaste, equivalente ao 4o sem dúvida!
Já agora que versão quantizada usaste?
unsloth Q6_K-xl UD . Segundo testes, equivale a um f16. Aqui: https://www.reddit.com/r/unsloth/comments/1n1jq1l/q5_k_xl_and_q6_k_xl_on_5shot_mmlu_graph/
Atenção é que, nestes chineses, 99,9999999999999999999999% dos valores investidos, nunca são referidos. Basta notar, que o governo chinês, colocou 6300000 milhões de dólares, nas empresas tecnológicas, em 2024. Esses valores, foram usados, sem que surjam em qualquer despesa, das empresas.