 Proponha uma correção, faça uma sugestão
Proponha uma correção, faça uma sugestão



Vamos transformar os seus Raspberry PI num cluster
O Apache Hadoop é uma Framework/Plataforma desenvolvida em Java, para computação distribuída, usada para processamento de grandes quantidades de informação (usando modelos de programação simples).
Depois de mostrarmos como instalar o Apache Hadoop no CentOS, hoje vamos ensinar a instalar no Raspberry PI.

Após a apresentação do Apache Hadoop, alguns leitores solicitaram-nos um tutorial para Ubuntu ou derivados. Para tal, recorremos ao Pipplware, mas tal tutorial pode ser aplicado em qualquer distribuição baseada no Ubuntu.
Com instalar o Apache Hadoop no Raspberry PI?
Para a instalação do Apache Hadoop no Raspberry PI devem seguir os seguintes passos:
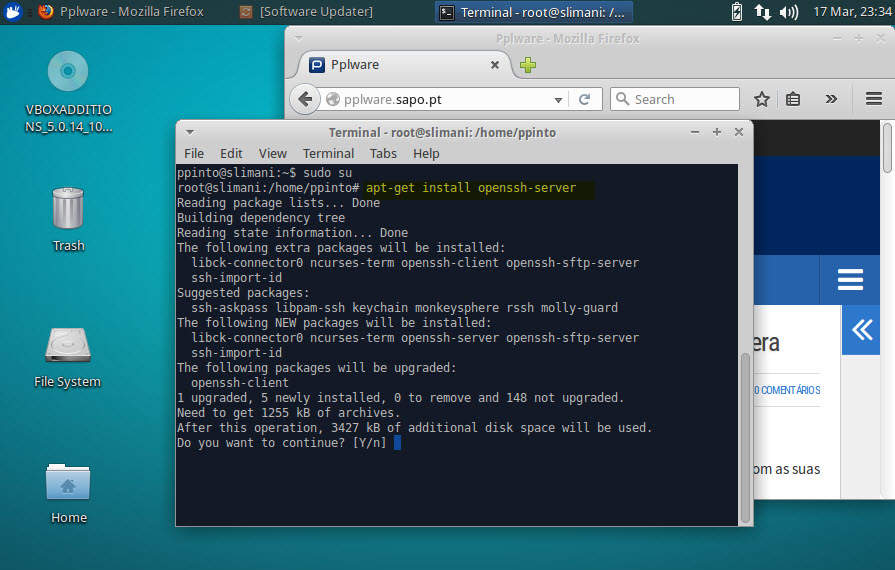
Passo 1) Instalar o servidor de SSH
sudo su apt-get install openssh-server |
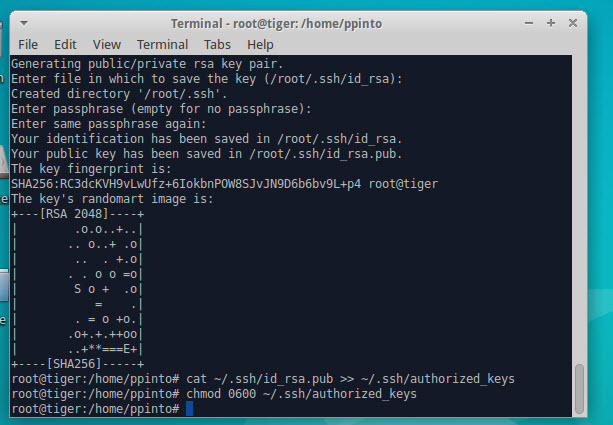
Passo 2) Criar chave SSH
ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys |
Passo 3) Instalar o Java
apt-get install openjdk-7-jdk |
Passo 4) Download e instalação do Apache Hadoop
wget https://www.apache.org/dist/hadoop/core/hadoop-2.7.0/hadoop-2.7.0.tar.gz tar xzf hadoop-2.7.0.tar.gz cp -rv hadoop-2.7.0 /usr/local/hadoop |
Passo 5) Definir variáveis de ambiente
Abrir o ficheiro ~/.bashrc usando o comando nano -w ~/.bashrc
e acrescentar as seguintes variáveis:
export HADOOP_PREFIX=/usr/local/hadoop export PATH=$PATH:$HADOOP_PREFIX/bin |
Passo 6) Definir JAVA_HOME
Vamos agora editar o ficheiro $HADOOP_PREFIX/etc/hadoop/hadoop-env.sh e definir a variável de ambiente JAVA_HOME.
Para editar o ficheiro basta que usem o comando nano -w $HADOOP_PREFIX/etc/hadoop/hadoop-env.sh

Nota: Quando executarem o cluster e caso tenham um erro no JAVA_HOME, definam esta variável também no ~/.bashrc. Ou simplesmente executem o comando export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64
O Apache Hadoop tem muitos ficheiros de configuração. Este ficheiros permitem as mais diversas configurações, de acordo com as necessidades de cada utilizador. Hoje vamos configurar um simples nó de um cluster para isso devem aceder a $HADOOP_HOME/etc/hadoop e alterar os seguintes ficheiros.
core-site.xml
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration> |
hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hadoopdata/hdfs/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hadoopdata/hdfs/datanode</value> </property> </configuration> |
mapred-site.xml
Nota: Caso não tenham este ficheiro, verifiquem se existe o ficheiro mapred-site.xml.template. Neste caso devem mudar o nome mapred-site.xml.template para mapred-site.xml.
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> |
yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> |
Passo 7) Criar utilizador e definir permissões
useradd hadoop passwd hadoop sudo chown -R hadoop /usr/local/hadoop/ |
Feitas as configurações nos ficheiros anteriores, vamos formatar o namenode usando o seguinte comando:
hdfs namenode –format |
Por fim vamos agora iniciar todos os serviços (com privilégios root) associados ao hadoop. Para tal basta que executem os seguintes comandos:
cd $HADOOP_PREFIX/sbin/ ./start-dfs.sh ./start-yarn.sh |
Para verificar se todos os serviços iniciaram correctamente, devem usar o comando jps e visualizar um output do tipo:
5536 DataNode 5693 SecondaryNameNode 5899 ResourceManager 6494 Jps 5408 NameNode 6026 NodeManager |
Aceder ao Apache Hadoop
Para aceder à interface de gestão do Apache Hadoop basta que abram um browser e introduzam o endereço http://localhost:8088

Para visualizar informações sobre o cluster basta que abram um browser e introduzam o endereço http://localhost:50070
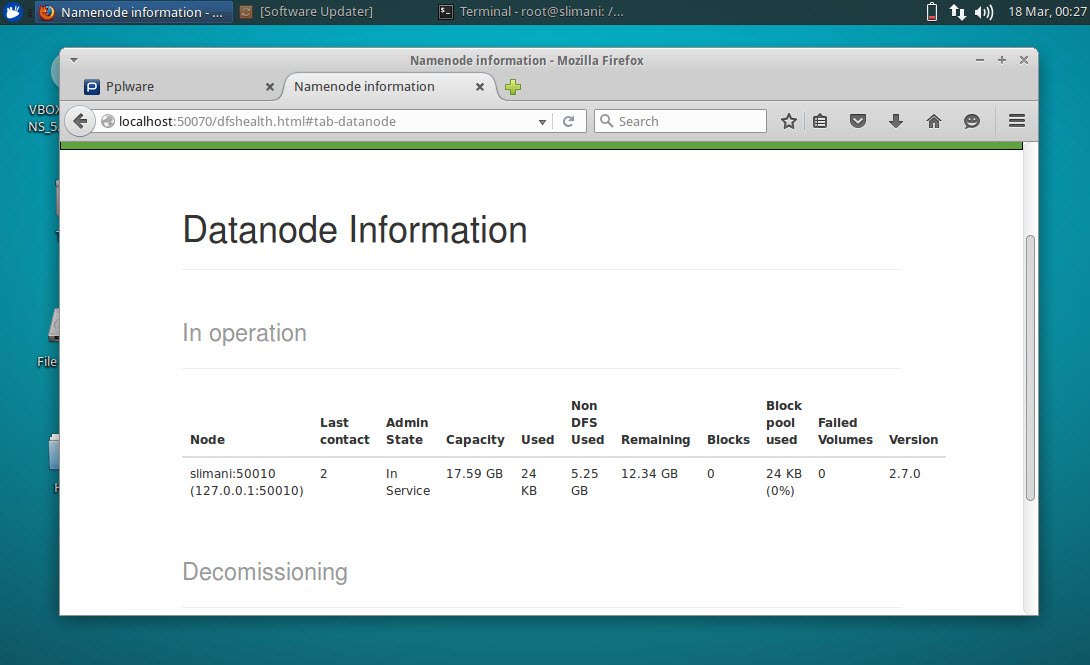
E está feito! Se tudo estiver a funcionar… Parabéns, você instalou com sucesso o Apache Hadoop! Num próximo artigo iremos ensinar como acrescentar, tal como prometido no artigo anterior, mais nós ao cluster.
Este artigo tem mais de um ano















Obrigado pela partilha, fico a aguardar próximo passo 🙂
Bom tudo bonitinho e tal mas… E na realidade, tem algum uso realmente útil?
Porque na realidade ainda não vi nada assim de outro mundo em relação a estes raspberries, parece tudo do mesmo, nada realmente útil, é apenas um brinquedo para experimentar coisas novas, só isso.
voce pode ter um supercomputador a baixo custo… eu ainda prefiro o banana pi. de qualquer maneira é uma revoluçao.
Não é nada do outro mundo, mas a economia de espaço para ter um cluster a disposição para processamento massivo paralelo de dados faz toda a diferença.
Onde posso arranjar uma estrutura destas para “encaixe” dos 3 Raspberry pi?
Muito legal o artigo.
Montar um cluster de Hadoop não é uma coisa para leigos e acrescentar cada vez mais nós, aí o bicho pega!
Vou colocar essa link nos meus preferidos porque a qualidade das matérias são muito boas.
Oi, eu tenho um RPI modelo 2 B+. Eu quero comprar um modelo 3 e para não deixar a outra de lado pensei em fazer um cluster com as 2. Posso fazer um cluster com 2 placas de modelo diferente?
Quando falamos em cluster, temos de entender que estamos falando de computação distribuida. A computação distribuida permite unir varios computadores heterogeneos, cada qual com sua caracteristica e obter um resultado especifico, seja ele de processamento, carga, disponibilidade (de acordo com a finalidade do cluster).
Então sim, pode-se usar equipamento com hardware diferente.
eu fico pensando se uma cluster de 10, 20 ou até 50 Raspberry PI conseguiria rodar um GTA V 4k ou battlefild V
Um cluster não é utilzado para jogos, o seu foco é processamento. Temos de entender a teoria da coisa.
Um cluster consiste em varios nós “escravos” recebendo uma determinada parte de uma tarefa definida pelo nó “mestre”. O nó mestre é resposavel por distribuidar as tarefas entre os demais nós, sendo assim ira utilizar o processamento de cada nó escravo para gerar a tarefa final ao nó mestre.
Agora imagine isso em um jogo, como seria possivel dividir toda ação de processamento do jogo aos demais nós e receber de volta ao nó controlador ao mesmo tempo? Seria algo insano, para o nó controlador fazer (pelo menos ao meu ponto de vista).
Quando falamos em cluster, temos de entender que estamos falando de computação distribuida. A computação distribuida permite unir varios computadores heterogeneos, cada qual com sua caracteristica e obter um resultado especifico, seja ele de processamento, carga, disponibilidade (de acordo com a finalidade do cluster).
Então sim, pode-se usar equipamento com hardware diferente.