










 Proponha uma correção, faça uma sugestão
Proponha uma correção, faça uma sugestão



Introdução ao debugging de software
Por Luís Soares para o PPLWARE.COM
O debugging de um programa baseia-se em alguns princípios e técnicas transversais à maioria das linguagens e ambientes de programação. Tentarei, neste artigo, sintetizar o que entendo por debugging, introduzindo o tema, colocando algumas luzes nos conceitos fundamentais e mostrando que há um mundo para além de alerts e prints.

Debugging (ou depuração) é o processo pelo qual se identificam e corrigem bugs de software (ou hardware). Dominar o debugging é vital para um programador: os bugs vão inevitavelmente aparecer quando a complexidade (número de programadores, de requisitos, de linhas de código, de dependências, etc.) aumentar. No início, fazer debug costuma ser algo chato e/ou custoso (pelo menos para mim, era); mas, com a prática, torna-se mais interessante, pois:
- faz-nos compreender melhor o workflow do programa, o que se passa “por baixo”, assim como tecnologias envolvidas;
- obriga a criar bom código que evita bugs semelhantes no futuro;
- alguns bugs estimulam a nossa capacidade de resolução de problemas e motivam-nos quando resolvidos.
Evitando o debug
A melhor forma de fazer debug é evitar ter de o fazer. Devemos adotar técnicas e boas práticas que reduzam a probabilidade de ter bugs e outras que facilitem a sua correção caso ocorram. Eis algumas (cuja explicação sai fora do âmbito atual):
- Code reviewing e Pair programming;
- Decoupling, encapsulamento e modularidade;
- Uso correto de design patterns;
- TDD;
- Redução de dependências (ex. de tecnologias, de pessoas, do S.O.);
- Uso de convention over configuration;
- Princípios SOLID;
- Não faça copy/paste de código (nunca vale a pena);
- Mantenha o código limpo e tenha pouco código;
- Faça bons comentários;
- entre muitas outras boas práticas...
O processo de debug
O debugging, apesar de muito ligado à programação, é uma disciplina com o seu próprio processo. Mesmo não se pensando nisso, está-se implicitamente a segui-lo:
- Reprodução: saber os passos a seguir, as condições iniciais, assunções, etc;
- Diagnóstico: gravidade, prioridade, impactos, riscos, a zona em causa. Para este último:
- Correção;
- Reflexão: aplicação de medidas que garantam que o problema não se repete noutro formato: testes, documentação, validações de input e corner cases, criação de código mais resiliente, refactoring, etc.

Logo na reprodução do problema é frequente que o programador perceba o que está mal, passando logo para a correção. Se isso não suceder, passa-se então ao diagnóstico (o debugging propriamente dito), altura em que são aplicadas as seguintes técnicas (entre muitas outras):
- Fazer reverse engineering: análise de outputs e stack traces, de dump files, de pacotes de rede, de padrões de comportamento, entre outros;
- Tentativa/erro: quando não se tem a certeza dos contornos do problema e se colocam diversas hipóteses, seguindo-se a sua eliminação progressiva;
- Isolar o problema: por exemplo, comentando código não relevante no problema ou criando um sample project com o problema na sua versão mais simples;
- Reverter o código gradualmente, até se perceber o que causou o problema;
- Tracing (prints): a técnica mais comum: imprimir que se passou em algum lado e/ou variáveis disponíveis momentos;
- Uso de debugger: ferramenta por excelência para debugging (inclui controlo de fluxo, avaliador de expressões, consola, profiler, entre outros utilitários).
Vejamos o tracing e o debugging com ferramenta em mais detalhe.
Imprimindo (tracing)
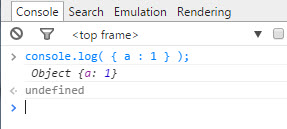
Quem nunca fez debug com prints? Tracing é o método mais usado para debug. Fazer tracing é usar a consola (há quem use a própria GUI, embora isso não seja muito elegante...) para imprimir (i.e. exibir) o estado do programa sem bloquear o seu fluxo. Por outras palavras, permite saber o valor de variáveis (ou simplesmente dizer que se passou lá) quando se passa nos sítios com prints. Pode ser usado para debugging ou apenas registo (logging). Eis alguns exemplos de prints em diferentes linguagens:
|
C |
printf("Olá\n") |
|
C++ |
cout << "Olá\n" |
|
Java |
System.out.println("Olá") System.err.println("Olá") |
|
C# / Visual Basic |
Console.WriteLine("Olá") |
|
Python |
print 'Olá' |
|
Objective C |
NSLog(@"Olá") |
|
JavaScript* |
console.info('Olá') console.log('Olá') console.warn('Olá') console.error('Olá') |
* Em JavaScript, não use o alert(…), pois:
- este quebra o fluxo aplicacional e bloqueia a interface;
- não imprime objetos (apenas exibe
[object Object]); - impede o correto funcionamento de alguns objetos do DOM (ex. IndexedDB).
Consoante o ambiente (linguagem, plataforma, IDE e bibliotecas) em uso, cada linha de tracing pode conter várias informações, entre as quais:
- Mensagem
- Data e hora
- Linha de código (para stack straces)
- Gravidade: varia com a linguagem e biblioteca. Ao fazer tracing, deve fazer uso do nível de gravidade correto. Os mais comuns são:
- Info: para registos gerais;
- Warning: para avisos e coisas que não deviam acontecer;
- Error: para erros de prováveis bugs (ex. SIGSEGV) e situações sem recuperação.
- Processo
- Aplicação
Características
- Simplicidade de uso; sempre presente e com poucos requisitos;
- Permite debug em tempo real pois não bloqueia o fluxo do programa; isto é especialmente patente quando não é possível fazer debug remoto e os prints no servidor são a única coisa que nos resta;
- Útil para análise de operações massivas, repetitivas, constantes, etc.;
- Útil para situações que podem ser inesperadas ou por perceber;
- Pode ser usado para manter registos (logging) para analisar mais tarde, lançar alarmística ou simplesmente guardá-los em arquivo;
- Muitas vezes, há limitações no que toca a imprimir objectos (tipos compostos);
- Só se pode ver o que se imprimiu… não há como voltar atrás;
- Imprimir é feito com instruções e portanto atrasa o programa;
- Se nos esquecermos de remover os prints, o código fica “sujo” (assim como o output/consola).
Deverá analisar as características da situação e perceber quando aplicar esta técnica. Muitas vezes, tem mais a ganhar recorrendo a debuggers...
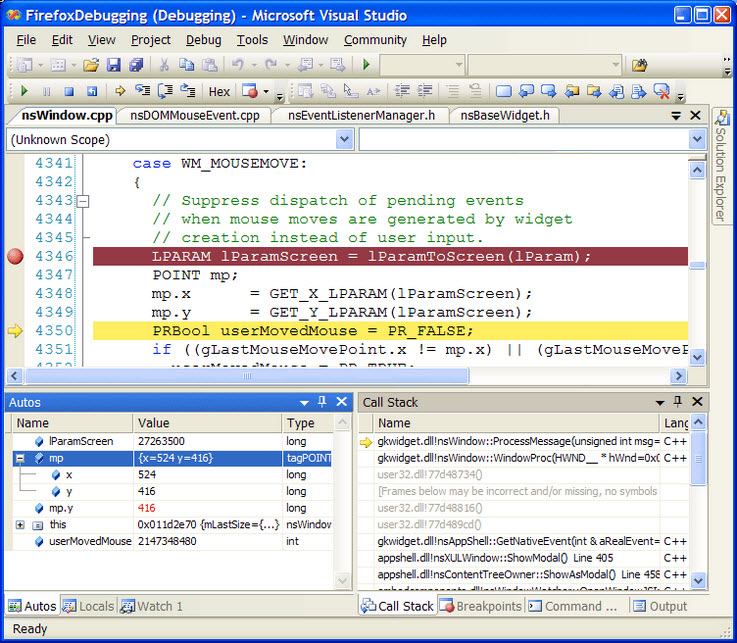
Recorrendo a debuggers
Imagine que houve um acidente em cadeia na autoestrada… Agora, tinha de identificar a causa do acidente. Poderia repetir tudo, tinha o poder de parar todos os veículos em simultâneo, podia tirar fotografias, analisar cada veículo, dar ordem para se prosseguir, etc. Esta metáfora ilustra o papel de um debugger de software: uma ferramenta de apoio ao debug sistematizado. Pode ser oferecido:
- de forma isolada (ex. DDD, Ideone);
- integrado no IDE (ex. Xcode, NetBeans, Eclipse);
- ou integrado noutra ferramenta (ex. Chrome Developer Tools: pressione F12 no seu browser).
Falar em detalhe num debugger exigiria um conjunto de artigos e tutoriais. Tentarei apenas resumir os conceitos principais e transversais a qualquer debugger e linguagem, os quais deve tentar dominar.
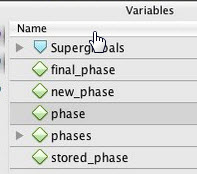
É importante que perceba que um programa a correr representa (pelo menos) um fluxo de execução (na prática, uma thread). O estado de um programa é o conjunto de elementos que o descrevem num determinado momento (o conjunto de todas as variáveis).
|
Controlo de fluxo |
||
|
Debug
|
|
A ordem que se dá para se iniciar em modo de debug. Um programa, quando lançado neste modo, abre uma sessão onde se consideram os restantes conceitos. |
|
|
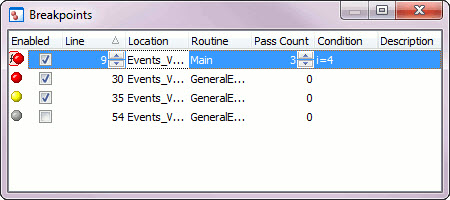
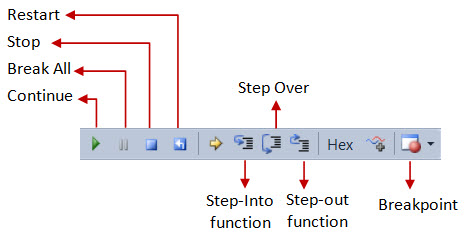
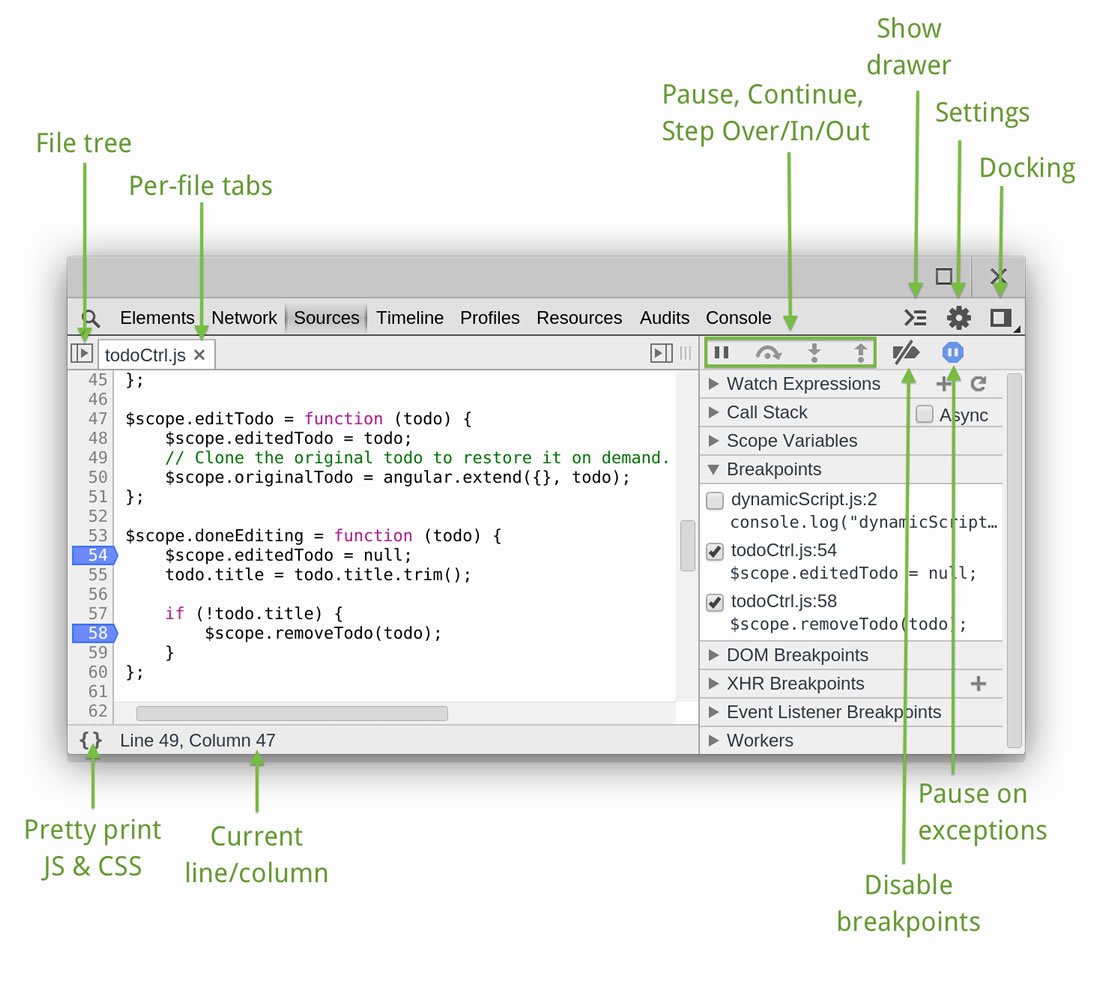
O conceito central do debugger. Breakpoints são marcadores colocados nas linhas do código-fonte, correspondendo a pedidos de bloqueio do fluxo. Por isso, sempre que o fluxo do programa pausa num breakpoint, foca o programador na linha respectiva ficando suspenso à espera de novas ordens. O programador pode então inspeccionar o estado da aplicação (com as ferramentas abaixo descritas).
|
|
|
Step ou Step over |
|
É a ordem do programador para seguir em frente um passo, ou seja, para a próxima instrução (geralmente a próxima linha) e voltar a pausar. |
|
Step into |
|
É a ordem de avançar um passo "entrando" na próxima invocação de função/método, voltando aí a pausar. |
|
Continue ou Resume |
|
A ordem para prosseguir, ou seja, de deixar o programa seguir o seu fluxo normal. Só se pausará no próximo breakpoint, caso exista e lá se passe. |
|
Stop |
|
A ordem para parar a sessão de debug. |
|
Estado |
||
|
Variables ou Scope Variables ou Locals |
|
O estado corrente, ou seja, o conjunto de variáveis do scope corrente (ex. locais, globais) e os seus valores do momento. Quando o programa pausa num breakpoint, podemos analisar este painel. Podemos até navegar nos objetos (drill down), no caso de programação O.O. De notar que a maioria dos debuggers permitem, ao passar o rato sobre uma expressão, saber o seu valor em “real time” (inspeção). |
|
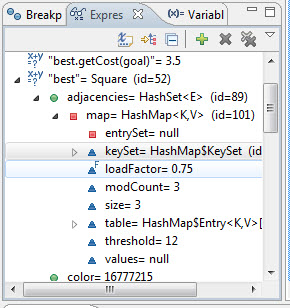
Watches ou Expressions ou Watch Expressions |
|
Quase o mesmo que Variables, mas estes são expressões “manualmente” definidas pelo programador. São como lupas apontadas continuamente a variáveis ou expressões exibindo o seu valor corrente. Sempre que se pausa num breakpoint, temos esta lista arbitrária de expressões que podemos analisar. |
|
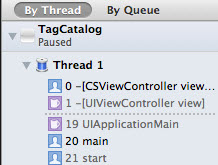
Call stack |
|
É a pilha de chamadas pendentes, aquando de uma pausa num breakpoint. Neste momento, podemos verificar o rol de chamadas que deu origem ao momento atual e estão à espera de voltar a ter o controlo. Quando há uma exceção, o call stack é imprimido na Consola, dando origem ao chamado stack trace. |
|
Console ou Output |
|
Onde é exibido o output, ou seja, o tracing do programador, do programa, do compilador, do servidor web, da BD, ... Por vezes, também é consola de input (ex. em JavaScript, no debugger do browser) (consola interativa). |
Características
- Total controlo sobre o fluxo (pausa, passo-a-passo, entrar em função,...);
- Fácil análise do estado corrente a qualquer momento (call stack, variáveis, expressões, watches, inspeção de objetos, ...);
- Permite o debug a bibliotecas de terceiros (se forem open source);
- Mais difícil de usar em multithreading;
- Necessário compilar e correr código em modo de debug (com IDE isto é implícito);
- É necessário ter e conhecer ferramenta de debugging;
- Não muito útil para análises de padrões ou que ainda não percebemos bem quando podem suceder;
- Não funciona para problemas causados por race conditions.
Tutoriais de debuggers
- Visual Studio
- DDD
- Xcode
- NetBeans
- Eclipse
- Android Studio
- IntelliJ IDEA
- Chrome Developer Tools
- Firefox Developer Tool
Em conclusão
Embora intimamente ligado à programação, o debugging tem o seu próprio processo: reprodução, diagnóstico, correção e reflexão. O diagnóstico é geralmente efetuado recorrendo a tracing - imprimindo - ou utilizando uma ferramenta: o debugger. Estas não são técnicas concorrentes. De facto, são muitas vezes usadas de forma complementar. Um debugger permite analisar à lupa um problema; o tracing permite análises gerais. Ambas passam por:
- Colocar de breakpoints e/ou prints nas zonas em causa;
- Lançar do programa e reproduzir o problema;
- Analisar do estado do programa quando ele passa pelas zonas em causa.
Os conceitos a reter e dominar num debugger são: breakpoints, steps, inspeção de objetos (variables e watches) e console
Quando o debugger é baseado na consola (ex. no GDB um step é um comando escrito), há desculpa para se recorrer ao tracing. Com as ferramentas gráficas disponíveis actualmente (varia com a linguagem), o tracing deve ficar relegado às suas funções. Este tem as suas limitações pelo que é fundamental que o programador domine o debugger. O problema é que se vêem programadores experientes a ignorar o seu poder, algo difícil de explicar (após o conhecerem, a sua produtividade aumenta e já não conseguem viver sem ele).
Possíveis tópicos a desenvolver em futuros artigos são os breakpoints condicionais e com hit count, o debugging remoto (ex. de um browser num telemóvel ou de uma aplicação web num servidor) e o uso de profiling.
Este artigo tem mais de um ano















Dos melhores artigos que por aqui passaram. Parabéns.
🙂
+1
Como introdução, 5*. E com os caminhos para aprofundar…
Para mim programador que não sabe usar um debuger não é programador. Obviamente estou a exagerar.
Na nossa empresa faz-nos muita confusão quando aparece um programador que não usa ferramentas de debug.
Em sistemas de baixo nível é vital a utilização de ferramentas de depuração.
Quem não utiliza debug é um génio!
Não, não estás a exagerar… 😉
Quem é o programador que não faz debug? não há…
se houver ele que me ensine como se faz 😀
Uma pequena mensagem de agradecimento pelo verdadeiro “serviço público” que têm vindo a fazer com estes tutoriais.
Além das noticias e artigos de opinião, este modelo de tutoriais que tem vindo a promover cada vez mais é muito positivo e de grande utilidade.
Um grande obrigado.
Abraços.
Parabéns pelo artigo!
Muito bom artigo, Parabéns.
Sei que sai fora do ambito deste mesmo artigo mas o debugg de microcontroladores é um outro mundo. Comparando o debugg destas linguagens de alto nível com o dos microcontroladores, este último torna-se bem mais interessante devido à componente de hardware associada ao software e a necessidade de corrigir erros, às vezes, mesmo no hardware, o que não são tão fáceis de detectar.
debug , pacht == crak windows, office keys…..
em C# e raro chegar ao asm.
ultimo degug apple wifi, herdware faill. patch in new MS,soft.
deguger que + uso -> colega do lado.
Tenta agora sem erros.
Artigo bem construído e muito construtivo(“cheio de polpa”). Vai muito além do bitaite:”Usem SEMPRE debug porque senão não são programadores.”
“Se debugging é o processo de remover bugs de software, a programação deve ser o processo de inserí-los”
– Edsger Dijkstra
Luis Soares,
Parabéns pelo artigo, está muito bom 😉
“Redução de dependências (ex. de tecnologias, de pessoas, do S.O.);”
Aqui depende, acho que aqui pensas-te mais do ponto de vista da Portabilidade…
Depende muito!
Tenho trabalhado com colegas que preferem usar e inventar alternativas a funções do SO, mas estas funções chegam a ser mais de 1000 vezes mais lentas…tudo porque não querem depender do SO, mas na prática o SO é linux e SEMPRE será… :S
Para quebrar essa lógica marado propus, uma API abstrata, que faz a verificação de qual SO está por baixo, e propus implementar o código necessário a usar funcionalidades do SO(para ser “Blazing Fast”), no meu caso linux(os que acham que a app pode em sonhos ser usada em Windows, que a implementem..)…
Tudo para dizer que depende muito do que estiveres a fazer, se velocidade for um requisito, então obrigatoriamente tens que usar as funcionalidades do SO!
Se a velocidade não for relevante, bem ai que se esqueça as Funcionalidades do SO, e opta por portabilidade, mas sempre salvaguardando uma API de acesso enxuta, e que futuramente te permita mais facilmente usares o SO..
Olá lmx,
Sim concordo. Julgo que as boas práticas não devem ser ambicionadas de forma cega e extremista (como no exemplo que deste). Devem haver equilíbrio e ponderação.
Quando falei em “redução de dependências” referia-me não só à portabilidade mas também à independência e autonomia de um projeto. Por exemplo: quão fácil é para um novo programador pegar no mesmo e corrê-lo? Quantos problemas tem de resolver? Com quantas pessoas tem de falar? Quantas alterações tem de fazer?
A ver se escrevo um artigo sobre independência de projetos. Já o fiz para independência de GUIs: http://luissoares.com/uma-interface-independente/
linux é linux mas em windows…… 1ª vm?
“””Generally, C# and Java can be just as fast or faster because the JIT compiler a compiler that compiles your IL the first time it’s executed can make optimizations that a C++ compiled program cannot because it can query the machine. It can determine if the machine is Intel or AMD; Pentium 4, Core Solo, or Core Duo; or if supports SSE4, etc.”””
http://www.codeproject.com/Articles/584743/Programming-Xlib-with-Mono-Deve
Sim o jit compiling é uma boa coisa 😉
O problema do JIT compiling, é mesmo na faze de warmup, e mesmo posteriormente, porque a faze de warmup é defenida por ti!
Tu podes decidir em que faze é que consideras a optimização a estar a determinado nivel de performance…
E claro a partir dessa faze, a optimização se existir é minima…
MAS durante o warmup, a APP quase nem se mexe!!!!
Gastas imenso cpu e memoria a potes para obter bons niveis de performance!
O Jit Compiling APENAS é bom para aplicações server side, e se for uma app que está em constante desenvolvimento…é uma desgraça por causa dos warmup times…necessarios a cada alteração que fazes.
O java ou C# podem ser mais rápidos que c++ em tarefas repetivas, como por exemplo alocar arrays de determinado tipo de objectos, etc…usando a memoria da VM…e que for previamente desalocada pelo Garbage colector(…será que ja foi desalocada…????pois é… a thread do GC é uma thread de baixa prioridade!!!!!!!Mais uma coisa a ter em atenção!!..para tarefas rápidas…esta teoria pode cair por terra…).
Depois no que toca a Funçôes do SO, não ha nada mais rápido que a própria API so SO, ou então uma API abstracta por cima(enxuta) que consoante o SO usa funções do SO onde vai ser executada!
Não te esqueças que a VM java ou .net é um processo que corre tal como qualquer outro..
Estamos a falar de coisas diferentes…eu estou a falar de interação entre a app e o SO , ficheiros, shared memory,etc…tu estas a falar da velocidade do código da propria app, mas não nestas fazes muitas das vezes cruciais.
Certamente se tens milhões de pedidos para analizar o tamanho de um ficheiro no disco, ou o tipo, etc…não o vais fazer em java…porque caso contrario vais “atascar” o cpu com processamente desnecessario, sendo que o tamanho dos ficheiros varia, o seus inodes no disco variam , os seus nomes variam, etc, etc, etc……………..
se fores profissional, vais criar uma API de abstração minima em C, que chama funções proprias do SO que foram desenvolvidas ao longo de décadas para serem “Blazing fast”…caso contrario estas a criar um Bottleneck!
No entanto se apenas tiveres meia duzia de ficheiros, aqui já depepnde…vais escrever muito e ler deles?
Se sim usa funções optimizadas para o efeito, se não epah usa aquilo que quiseres, porque não é muito relevante.
Cada caso é um caso..
100% de acordo n
Obrigado pelos comentários! vou tentar continuar a escrever 🙂
Excelente artigo! Parabéns e obrigado pelo trabalho desenvolvido em benefício daqueles que desejam aprimorar seus conhecimentos.