Anteriormente vimos como é possível representar, modelar e atribuir semântica a dados descritos em RDF. Hoje vamos ver como podemos realizar consultas ou inquéritos (queries) sobre esses dados utilizando SPARQL.


O que é o SPARQL?
SPARQL é um acrónimo recursivo (em inglês) que significa SPARQL Protocol and RDF Query Language. Assim, este é simultaneamente um protocolo e uma linguagem de consulta (ou de inquéritos) a dados representados em RDF.
Resumidamente, como linguagem de consulta, o SPARQL é usado para realizar inquéritos a dados representados em RDF de uma forma semelhante ao modo como se usa o SQL – Structured Query Language para consultar dados em bases de dados relacionais ou o XQuery para consultar dados representados em XML.
Como protocolo, o SPARQL assenta em serviços HTTP para transmitir consultas (queries) SPARQL e respetivos resultados entre uma aplicação cliente e um SPARQL Endpoint. Neste contexto, denomina-se de SPARQL Endpoint um servidor HTTP que expõe dados através do protocolo SPARQL. Uma lista (incompleta) de SPARQL Endpoint acessíveis na web pode ser consultada aqui.
Neste artigo iremo-nos focar apenas em descrever o SPARQL como linguagem de consulta.
Conceitos Básicos
As consultas SPARQL atuam sobre bases de conhecimento onde os dados estão representados em RDF. Recorde que (i) em RDF os dados são representados por meio de triplos na forma de sujeito, predicado, objeto; e (ii) um grafo RDF consiste num conjunto de triplos, podendo esse grafo ter um nome (na forma de IRI) associado. Neste contexto, uma base de conhecimento consiste num ou mais grafos RDF. Neste artigo vamos recorrer, mais uma vez, à base de conhecimento usada nos artigos anteriores e graficamente representada na Figura 1 para suportar os exemplos apresentados.
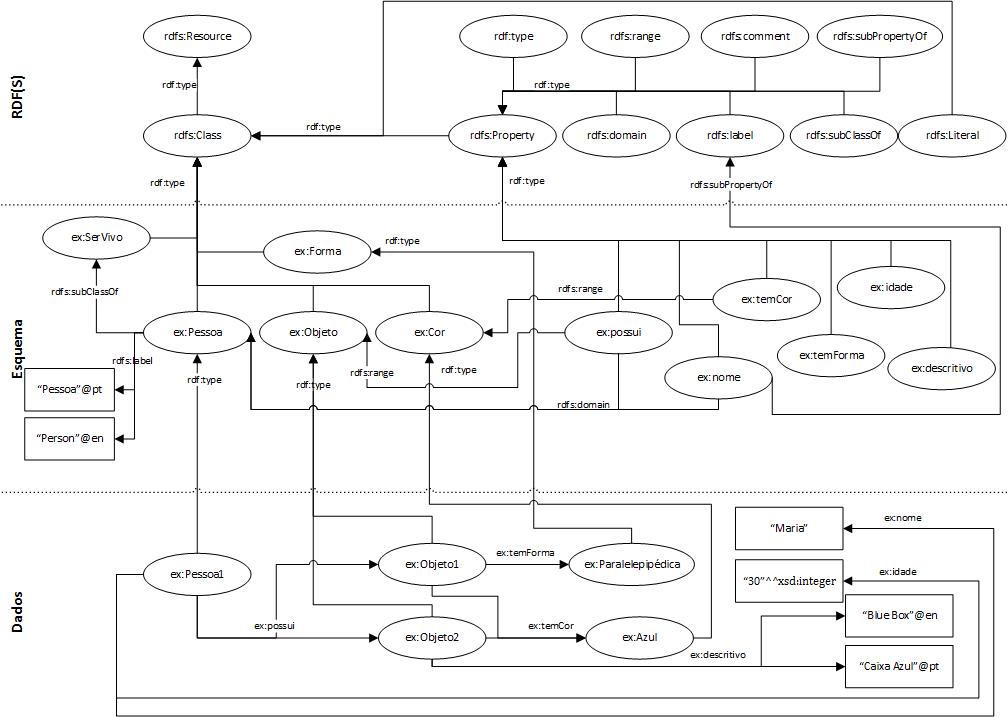
Figura 1 Base de Conhecimento usada como exemplo para realização de consultas SPARQL.
De uma forma simples pode-se dizer que uma consulta SPARQL consiste na especificação de um grafo RDF onde alguns dos nós do grafo são substituídos por variáveis. Por exemplo, o grafo seguinte:
?obj rdf:type ex:Objeto
é composto apenas por um triplo, sendo que o sujeito desse triplo (?obj) é uma variável. Em SPARQL, as variáveis começam por um ponto de interrogação (“?”) e podem ser usadas em qualquer parte do(s) triplo(s). Denomina-se de grafo padrão (graph pattern) um grafo RDF especificado com variáveis. Os resultados da consulta, decorrem das correspondências (matching) encontradas para o grafo padrão na base de conhecimento. Cada correspondência resulta da atribuição (binding) de valores (i.e. nós RDF) a todas as variáveis de forma a satisfazer o padrão especificado. Assim, ao especificarmos um grafo padrão, estamos a especificar as condições que os dados da base de conhecimento devem satisfazer para serem apresentados como uma solução para a consulta realizada.
Considerando a nossa base de conhecimento, o grafo padrão anterior é satisfeito só em duas ocasiões. Uma quando se atribui o nó ex:Objeto1 à variável ?obj e a outra quando se atribui o nó ex:Objeto2 à mesma variável. Consequentemente, podemos dizer que o grafo padrão anterior tem apenas duas soluções.
Por fim, salienta-se que na especificação de um grafo padrão não existem restrições relativamente à quantidade de triplos e de variáveis usadas. Mais, no limite, poderá haver triplos especificados recorrendo apenas a variáveis (e.g. ?sub ?pred ?obj).
Exemplo Prático
Para introduzir as principais cláusulas (ou palavras reservadas) de uma consulta SPARQL vamos recorrer a um exemplo prático. Assim, considere que se pretende construir uma consulta SPARQL para conhecer cinco objetos azuis (i.e. que têm a cor azul) existentes na nossa base de conhecimento e, caso existam, a descrição respetiva de cada um desses objetos. Para responder a esta questão podemos especificar a seguinte consulta.
1 PREFIX ex: <https://pplware.sapo.pt/sw/>
2 PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
3 SELECT ?obj ?desc
4 WHERE {
5 ?obj ref:type ex:Objeto.
6 ?obj ex:temCor ex:Azul.
7 OPTIONAL (?obj ex:descritivo ?desc).
8 }
9 LIMIT 5
Esta consulta começa por fazer uso da palavra reservada PREFIX para declarar os prefixos ex e rdf com o intuito de abreviar os IRI dos recursos que vão ser mencionados no grafo padrão. Deste modo podemos usar, por exemplo, ex:temCor para nos referirmos ao recurso <https://pplware.sapo.pt/sw/temCor>. A declaração de prefixos é opcional e, portanto, se não for definido nenhum prefixo deve-se usar o IRI completo dos recursos mencionados.
A palavra reservada SELECT é uma das quatro cláusulas de retorno possíveis de usar (cf. secção seguinte) e, talvez, seja a mais utilizada. Esta permite discriminar quais são as variáveis do grafo padrão usadas para projetar os resultados da consulta (e.g. ?obj e ?desc). Note-se que o grafo padrão pode conter mais variáveis do que as discriminadas aqui.
O grafo padrão da consulta é especificado recorrendo à cláusula WHERE (linhas 4 a 8). Basicamente, é aqui que se define o propósito da consulta. No nosso exemplo, o triplo especificado na linha 5 permite conhecer todos os recursos (dados por ?obj) que são objetos (ex:Objeto). Por outro lado, o triplo especificado na linha 6 acrescenta que apenas estamos interessados nos recursos dados por ?obj que têm a cor (ex:temCor) azul (ex:Azul). Assim, em conjunto estes dois triplos permitem-nos conhecer todos os objetos azuis. Para conhecer a descrição (?desc) de cada objeto podemos recorrer ao triplo especificado na linha 7 como opcional (OPTIONAL). Como o nome indica, o uso desta palavra reservada permite especificar triplos cuja existência é desejável mas não obrigatória para encontrar uma solução para a consulta realizada. Desta forma, no nosso exemplo, os objetos azuis que não tenham uma descrição não são excluídos dos resultados.
A cláusula LIMIT é um dos vários modificadores que podem ser usados para organizar e restringir os resultados de uma consulta. Neste caso, o LIMIT é usado para indicar a quantidade máxima de resultados em que se está interessado (e.g. no nosso exemplo são 5). Outros modificadores muito comummente usados são:
- FILTER: usado para especificar outras condições para além das constantes no grafo padrão de forma a restringir ainda mais os resultados da consulta (e.g. a descrição dos objetos tem que ser em português, i.e. “@pt” );
- ORDER BY: usado para especificar o critério pelo qual os resultados devem ser ordenados;
- OFFSET: usado para indicar que pretendemos ignorar os N primeiros resultados (e.g. OFFSET 10 não retorna os primeiros 10 resultados da consulta).
Os uso combinado dos modificadores ORDER BY, LIMIT e OFFSET permite paginar os resultados das consultas.
Os resultados de uma consulta deste género (i.e. Select) são tipicamente representados numa tabela, onde cada linha corresponde a um resultado, e cada coluna ao valor de uma variável especifica. Cada resultado, representa uma solução para as condições especificadas no grafo padrão. A Tabela 1 apresenta o resultado da execução da consulta SPARQL exemplo sobre a nossa base de conhecimento.
Tabela 1 Resultados da consulta SPARQL exemplo.
| obj | desc |
| <https://pplware.sapo.pt/sw/Objeto1> | |
| <https://pplware.sapo.pt/sw/Objeto2> | “Blue Box”@en |
| <https://pplware.sapo.pt/sw/Objeto2> | “Caixa Azul”@pt |
Provavelmente, os leitores mais familiarizados com o SQL estão neste momento a questionar-se se em SPARQL, ao contrário do que acontece em SQL, não é necessário especificar ao nível da consulta qual é a origem dos dados (e.g. em SQL isto é feito através da cláusula FROM). Em SPARQL existem duas cláusulas para esse efeito (FROM e FROM NAMED), contudo, ambas são opcionais. A cláusula FROM permite especificar o IRI da(s) base(s) de conhecimento a inquirir. Por outro lado, a cláusula FROM NAMED permite especificar o(s) grafos (pelo seu IRI) d(s) base(s) de conhecimento inquiridas donde se pretende obter.
Cláusulas de Retorno
Para além da cláusula de retorno SELECT, existem outras três cláusula de retorno que podem ser usadas em alternativa: a ASK, a DESCRIBE e a CONSTRUCT.
A cláusula ASK é usada quando se pretende verificar se existe pelo menos um resultado na base de conhecimento que satisfaça o grafo padrão da consulta. Se existe, a consulta retorna “verdadeiro” (true), caso contrário, retorna “falso” (false).
A cláusula DESCRIBE é usada para obter um grafo RDF cuja informação descreve o recurso indicado na consulta. Relativamente a esta cláusula convém salientar que para a mesma base de conhecimento e recurso consultado, o conteúdo do grafo RDF resultante pode variar em função da implementação e/ou configuração do motor (engine) SPARQL que executa a consulta.
A cláusula CONSTRUCT é usada tipicamente para transformar dados descritos de acordo com um esquema (i.e. o da base de conhecimento inquirida) em dados descritos de acordo com outro esquema. Com efeito, esta cláusula gera um novo grafo RDF a partir de um modelo (template) especificado como parte da própria consulta. Os resultados da consulta são usados para preencher os valores das variáveis constantes no modelo especificado. O uso deste tipo de consultas é muito comum em cenários que exigem integração ou tradução de dados de um sistema para outro.
Conclusões
Conclui-se esta breve introdução ao SPARQL salientando, mais uma vez, que o SPARQL é simultaneamente uma linguagem de consulta de dados representados em RDF e um protocolo para transmissão dessas consultas e resultados entre uma qualquer aplicação cliente e um SPARQL Endpoint.
Neste artigo focamo-nos em apresentar os principais conceitos e cláusulas da linguagem de consulta do SPARQL através de um exemplo prático. Contudo, muitas outras cláusulas e funcionalidades ficaram por abordar como, por exemplo, o uso de funções de agregação, alteração dos dados constantes na base de conhecimento e uso de operadores de negação. Atendendo à importância destas e doutras funcionalidades, desde já fica o compromisso de nos versarmos sobre elas em futuros artigos.
Por hoje é tudo! Esperamos que tenha gostado e deixe a sua opinião.