Os debates sobre os benchmarks de inteligência artificial (IA) e a forma como as empresas os apresentam estão a tornar-se cada vez mais visíveis ao público. Esta semana, um funcionário da OpenAI acusou a empresa de IA de Elon Musk, a xAI, de publicar resultados de benchmarks enganosos para o seu mais recente modelo, o Grok 3.

Afinal, o Grok 3 não é assim tão bom?
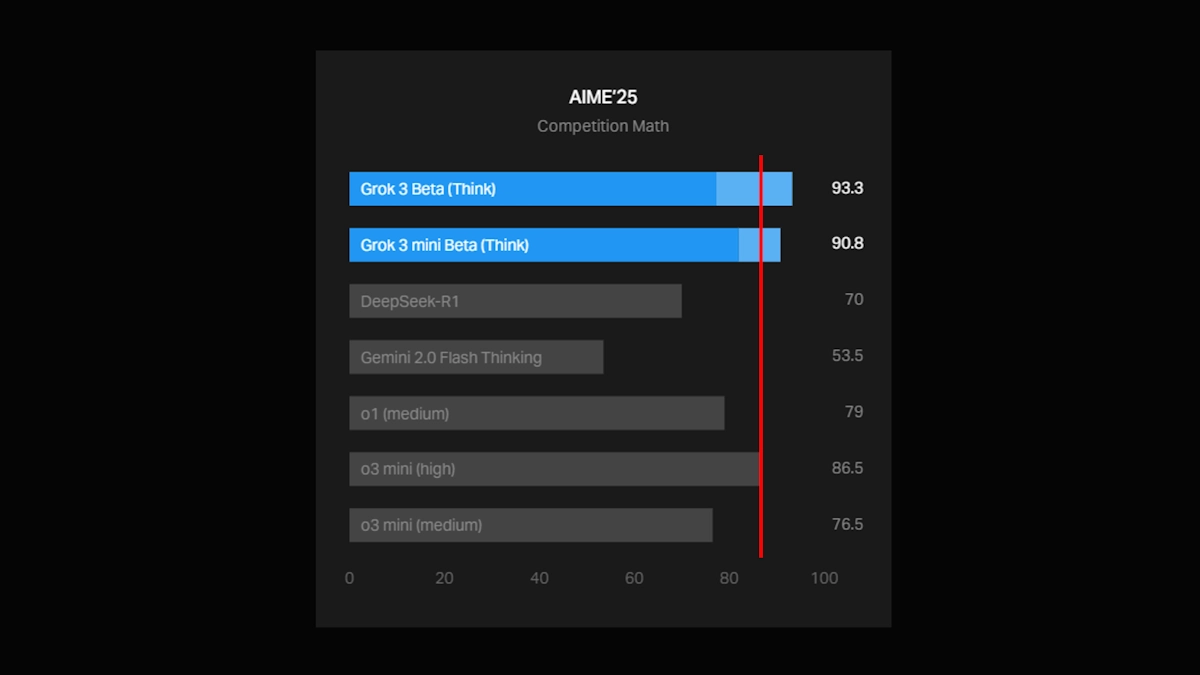
Num artigo publicado no blog da xAI, a empresa divulgou um gráfico com o desempenho do Grok 3 no AIME 2025, um conjunto de perguntas matemáticas desafiantes extraídas de um exame recente de matemática competitiva.
Embora alguns especialistas questionem a validade do AIME como benchmark para IA, este é frequentemente utilizado para avaliar a capacidade matemática dos modelos.
O gráfico da xAI mostrava duas variantes do Grok 3 – o Grok 3 Reasoning Beta e o Grok 3 mini Reasoning – a superar o melhor modelo da OpenAI disponível, o o3-mini-high, no AIME 2025. No entanto, funcionários da OpenAI rapidamente apontaram, no X, que a xAI omitiu o resultado do o3-mini-high quando avaliado a “cons@64”.
cons@64
Esta métrica, abreviação de “consensus@64”, permite ao modelo tentar responder a cada problema 64 vezes e selecionar a resposta mais recorrente como a final. Este método tende a aumentar significativamente a pontuação dos modelos nos benchmarks e, ao não incluí-lo no gráfico, pode dar a impressão errada de que um modelo supera outro, quando na realidade isso pode não ser verdade.
Se analisarmos os resultados do Grok 3 Reasoning Beta e do Grok 3 mini Reasoning Beta com a métrica “@1” – ou seja, a primeira resposta dada pelos modelos sem repetição – verificamos que ambos ficaram abaixo do o3-mini-high.
Barra azul clara (cons@64); Barra azul escura (cons@1).
O Grok 3 Reasoning Beta ficou ainda ligeiramente atrás do modelo o1 da OpenAI configurado para “medium” computing. Ainda assim, a xAI continua a promover o Grok 3 como a “IA mais inteligente do mundo”.
xAI acusa OpenAI de também já ter feito o mesmo…
Igor Babushkin contra-argumentou no X que a OpenAI também já publicou gráficos potencialmente enganadores no passado, embora apenas ao comparar os seus próprios modelos. Entretanto, um investigador independente compilou um gráfico “mais preciso” que apresenta o desempenho de vários modelos com a métrica cons@64.
Contudo, como destacou o investigador de IA Nathan Lambert, um dos fatores mais relevantes continua desconhecido: o custo computacional e monetário necessário para cada modelo atingir a sua melhor pontuação. Este detalhe sublinha como os benchmarks, por si só, comunicam muito pouco sobre as verdadeiras limitações e capacidades dos modelos de IA.
Leia também: