Desde os primórdios da informática que existem duas operações que andam de mãos dadas: guardar informação e obter essa mesma informação de volta. Estas operações, por mais simples que pareçam, têm as suas dificuldades e são elas que vão determinar em grande parte a fiabilidade e a eficiência de todo o sistema envolvente.
Hoje contamos-lhe a história do início das Bases de Dados.

Os processos de guardar e de obter dados são dos mais importantes no software de hoje em dia. Por isso, para minimizar o tempo de resposta do sistema aquando destas operações, é preciso que as formas com que acedemos à memória sejam inteligentes e eficazes.
Inicialmente, a única solução que os programadores tinham era de guardar os dados das suas aplicações em ficheiros. Esta situação levanta uma série de questões:
- é complicado manipular ficheiros, principalmente quando é necessário lidar com vários em simultâneo
- a eficiência desta lógica era baixa, por exemplo, para ir buscar um cliente, teria que se carregar todos os clientes para memória e só depois aplicar o filtro (e talvez fosse necessário carregar outros ficheiros dependendo da organização da informação)
- se um registo fosse mal guardado poderia comprometer todo o ficheiro e os que com ele se relacionam
- não há abstração nenhuma entre a manipulação dos dados e a maneira como eles foram guardados
Como resolver estes problemas?
Para solucionar estes problemas, por volta dos anos 60, surgiram os primeiros sistemas de gestão de bases de dados (SGBD) – um conjunto de ficheiros organizados que tinha como principal objetivo retirar da aplicação cliente a responsabilidade de gerir o acesso, a persistência, a manipulação e a organização dos dados.

Estes SGBD seguiam o modelo de navegação – modelo procedimental que permitia ao programador escolher um caminho arbitrário seguindo as relações de registo para registo, idêntico a um grafo ou uma rede.
Facto curioso é que este modelo apenas foi possível com a criação do disco magnético, pois este permitia um acesso random aos dados armazenados, ou seja, o programador podia saltar entre zonas não contíguas do disco, ao contrário dos seus antecessores (como a fita e cartões perfurados) que obrigavam a ler os dados armazenados de forma sequencial.
Charles Bachman foi um dos grandes impulsionadores deste modelo, o qual usou para construir um dos primeiros SGBD, o IDS (Integrated Data Store).

Aparecimento do modelo relacional e do SQL
Apesar do modelo de navegação resolver muitos dos problemas referidos, continuava a haver um sério problema por resolver. Caso a estrutura interna dos dados fosse mudada, os programas que usavam esses mesmos dados tinham que ser todos alterados e reestruturados, pois continuava a não haver a abstração entre a aplicação cliente e os dados.
Em 1970, enquanto trabalhava para a IBM, Edgar Frank Codd, descontente com esta situação, publicou o seu artigo “A Relational Model of Data for Large Shared Data Banks” onde descreveu o conceito de modelo relacional – modelo baseado na teoria de conjuntos em que uma base de dados é vista como uma coleção de relações (nos SGBDs são as tabelas), que, por sua vez, são conjuntos de tuplos (linhas nos SGBDs), que são grupos de atributos (colunas nos SGBDs).
Este modelo permite, através das suas características, que os dados sejam completamente desacoplados da aplicação, visto que já não se acede aos dados de uma maneira procedimental.
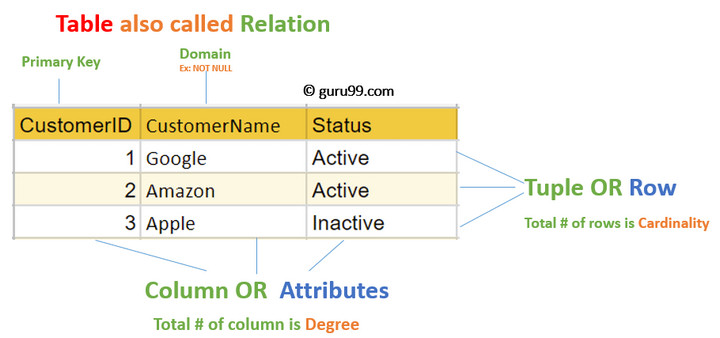
Modelo Relacional
Em 1973, dois cientistas da Universidade de Berkeley, Michael Stonebraker e Eugene Wong, leram o trabalho publicado por Codd e ficaram muito interessados na ideia do modelo relacional.
Nesta altura, estes dois cientistas estavam na posse de fundos que tinham angariado para a pesquisa de um sistema de base de dados geográfica para o grupo de economia da Universidade de Berkeley, o Ingres (INteractive Graphics REtrieval System). Mas, visto o seu interesse e entusiasmo com o modelo relacional, Stonebraker e Wong decidiram usar esse dinheiro não para o seu destino original, mas sim para um SGBD relacional ao qual deram o mesmo nome do sistema de base de dados que era suposto ser feito à partida.
Ao mesmo tempo, desenvolveram a linguagem de consulta que iria ser usada para pesquisar e alterar a base de dados, a QUEL.
Entretanto, dois jovens que na altura, tal como Edgar F. Codd, trabalhavam na IBM, Donald D. Chamberlin e Raymond F. Boyce, inspirados pelo modelo relacional, desenvolveram uma linguagem declarativa idêntica ao QUEL, mas com mais funcionalidades, com o objetivo de manipular e de obter dados guardados do System R, a base de dados relacional que a IBM estava a desenvolver na altura. Essa linguagem era o SEQUEL – Structured English Query Language ou, em português, Linguagem Estruturada de Consulta em Inglês, mais tarde abreviado para SQL.

Estes dois SGBDs demonstraram que bases de dados relacionais podiam ser eficazes e eficientes, validando assim o modelo relacional e revolucionando o mundo informático com este novo paradigma.
Resumo (e algumas curiosidades):
- 1963: Charles Bachman lança o IDS, um dos primeiros SGBDs do mundo
- 1970: Edgar Frank Codd publica o seu artigo onde explica o seu conceito de modelo relacional
- 1973: Charles Bachman ganha o Prémio de Turing pelo seu modelo de navegação e publica, devido a este acontecimento, “The Programmer as Navigator”- Michael Stonebraker e Eugene Wong começam a trabalhar no Ingres e no QUEL
- 1974: o System R começa a ser desenvolvido e o SQL é desenhado por Donald D. Chamberlin e Raymond F. Boyce- lançado um primeiro protótipo do Ingres
- 1977: System R tem o seu primeiro cliente, Pratt & Whitney
- 1981: Edgar F. Codd ganha o Prémio de Turing devido ao seu modelo relacional, publicando “1981 Turing Award Lecture – Relational Database: A Practical Foundation for Productivity“
- 2014: Graças às suas fundamentais contribuições para os conceitos e práticas subjacentes aos modernos SGBDs, Michael Stonebraker recebe o Prémio de Turing
O SQL, usado ainda hoje em bases de dados de alta performance, é provavelmente das linguagens mais importantes na história da computação. No entanto, o SQL é apenas uma linguagem e precisa que haja programas que explorem ao máximo as suas potencialidades, tal como o System R. Estes programas são os já referidos SGBD. Por isso, devido à importância que estes têm, no próximo artigo de “A História das Bases de Dados” serão abordados os principais e mais marcantes SGBD relacionais e a sua história.