Agora que estamos familiarizados com o conceito de ontologia podemos focar-nos em conhecer a principal linguagem de representação de ontologias da Web Semântica. Assim, hoje vamos conhecer o OWL – Web Ontology Language.


Uma ontologia é o artefacto através do qual se captura e partilha a terminologia, a estrutura e a semântica com que se pretende descrever os dados de um determinado domínio de conhecimento. Consequentemente, o que uma linguagem de representação de ontologias permite é especificar essa mesma terminologia, estrutura e semântica ou, posto de uma forma mais simples, permite especificar o esquema dos dados. Com este intuito, e provavelmente os nossos leitores mais atentos recordar-se-ão, já apresentamos anteriormente neste espaço o RDF Schema (cf. aqui e aqui). Contudo, este apenas disponibiliza um conjunto de capacidades básicas para esse efeito. A este respeito, salienta‑se algumas das limitações tipicamente associadas ao RDF Schema:
- Não suporta a definição de novas classes por combinação (e.g. união, interseção, negação) de outras classes já existentes;
- Não permite restringir o contradomínio (range) e/ou a cardinalidade de uma propriedade ao nível de uma classe;
- Não providencia vocabulário e, consequentemente, semântica para caracterizar adequadamente as propriedades como sendo, por exemplo, transitivas, funcionais, (as)simétricas, (ir)reflexivas.
Em suma, considera-se que a expressividade do RDF Schema é insuficiente para satisfazer adequadamente um vasto leque de necessidades associadas à modelação de dados e, em particular, no contexto da Web Semântica. Com o objetivo de colmatar esta insuficiência surge, como uma extensão ao RDF Schema, o OWL. Como recomendação da W3C, a sua primeira versão (OWL 1) data de fevereiro de 2004. A sua versão mais recente (OWL 2) data de dezembro de 2012. A descrição disponibilizada neste artigo tem como referência a versão mais atual.
Na conceção do OWL foram considerados outros objetivos para além dos já mencionados. Neste particular, destaca-se o objetivo de evitar/minimizar qualquer complexidade desnecessária que possa desencorajar a sua adoção. Nesse sentido, o mesmo foi concebido para (i) ser fácil de usar; (ii) potenciar a reutilização e partilha de ontologias já existentes bem como facilitar a sua manutenção e evolução; (iii) fomentar a interoperabilidade entre ontologias; (iv) permitir a deteção de inconsistências lógicas; e (v) proporcionar um equilíbrio entre expressividade e escalabilidade de acordo com o cenário aplicacional em causa. Uma descrição mais detalhada sobre estes e outros objetivos está disponível aqui.
Estrutura de uma Ontologia
A Figura 1 representa a estrutura de uma ontologia em OWL 2. Nesta percebe-se que uma ontologia é constituída por um conjunto de entidades (Entity). Qualquer entidade tem necessariamente um identificador único (IRI). Para além das entidades, uma ontologia contem um conjunto de restrições (ClassExpression) e de literais (Literal). As restrições permitem capturar conhecimento adicional sobre o domínio explorando as entidades (i.e., vocabulário) existentes. Um literal representa sob a forma de texto (String) um qualquer valor (e.g. “50” ou “Portugal” ou “27-05-2004”), tendo a si associado o tipo de dados (Datatype) com que esse valor deve ser interpretado (e.g. número inteiro ou texto ou data). Numa perspetiva mais genérica, pode-se dizer que um tipo de dados representa um intervalo de valores (DataRange) usado para restringir os valores admissíveis para um dado literal.
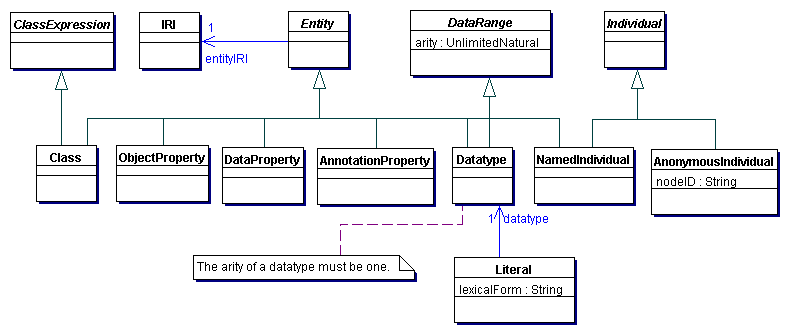
Figura 1: Estrutura de uma ontologia em OWL 2.
(Retirado de http://www.w3.org/TR/owl2-syntax/).
Cada entidade (Entity) de uma ontologia pode ser categorizada, entre outras, como classe (Class), indivíduo (Individual), propriedade de relação (ObjectProperty) e propriedade de dados (DataProperty).
Uma classe (Class) identifica e representa um conjunto de elementos reais do domínio de conhecimento em causa, vulgarmente designados de indivíduos (Individual) ou de instâncias da classe. Por exemplo, numa ontologia sobre animais podemos especificar (i) a classe ex:Animal (onde “ex” corresponde ao prefixo “https://pplware.sapo.pt/sw/”) para representar o conjunto de todos os animais; e (ii) os indivíduos ex:bobby e ex:tareco como membros dessa classe. Esta especificação resulta nos seguintes triplos:
ex:Animal rdf:type owl:Class
ex:bobby rdf:type ex:Animal
ex:tareco rdf:type ex:Animal
Os indivíduos explicitamente definidos na ontologia (e.g. ex:bobby) denominam-se de indivíduos conhecidos ou com nome (NamedIndividual). Adicionalmente, no âmbito de uma ontologia pode ser deduzida, através de mecanismos de inferência, a existência de outros indivíduos. Estes indivíduos são comummente designados de indivíduos anónimos (AnonymousIndividual). Ao contrário do que acontece com os indivíduos conhecidos, a existência dos indivíduos anónimos está consignada à própria ontologia e, portanto, não são mencionáveis fora da ontologia.
Uma propriedade de relação (ObjectProperty) permite estabelecer relacionamentos entre indivíduos. Por outro lado, uma propriedade de dados (DataProperty) permite estabelecer relacionamentos entre indivíduos e literais. No contexto da nossa ontologia sobre animais podemos, por exemplo, especificar a propriedade de relação ex:convive com o intuito de conhecermos quais são os animais que convivem uns com os outros e a propriedade de dados ex:nome com o intuito de conhecermos o nome de cada animal. Admitindo que “Bobby I” e “Tareco J.” são respetivamente o nome de ex:bobby e ex:tareco e que ambos convivem um com o outro, esta especificação resulta nos seguintes triplos:
ex:convive rdf:type owl:ObjectProperty
ex:nome rdf:type owl:DatatypeProperty
ex:bobby ex:nome “Bobby I”
ex:tareco ex:nome “Tareco J.”
ex:bobby ex:convive ex:tareco
ex:tareco ex:convive ex:bobby
Ao contrário das propriedades de relação e de dados que tipicamente se aplicam apenas sobre os indivíduos da ontologia, as propriedades de anotação (AnnotationProperty) aplicam-se sobre todas as entidades da ontologia (e.g. classes, indivíduos, propriedades de relação e de dados) com o objetivo de capturar notas (e.g. rótulos, comentários, observações) sobre as mesmas. Com efeito, aquando da especificação de uma ontologia, não é comum definirem-se novas propriedades de anotação. Em vez disso, usam-se as propriedades de anotação existentes no RDF Schema (e.g. rdfs:label, rdfs:comment, rdfs:seeAlso) e no próprio OWL (e.g. owl:versionInfo, owl:priorversion, owl:incompatibleWith). A titulo de exemplo, apresenta-se duas anotações para a classe ex:Animal:
ex:Animal rdfs:label “Animal”@pt
ex:Animal rdfs:label “Animal”@enatravés das quais se especifica um rótulo (label) em português e outro em inglês respetivamente.
Perfis
A linguagem OWL suporta o conceito de perfil (profile). Neste contexto, um perfil (também comummente designado de dialeto ou de fragmento) consiste numa versão mais reduzida da linguagem, especificada através de um conjunto de restrições associadas ao uso dos elementos (constructs) da própria linguagem. A especificação de um perfil visa estabelecer um compromisso entre (i) o grau máximo de formalidade (ou expressividade) de uma ontologia e, dessa forma, os tipos de inferência possíveis de realizar e (ii) o desempenho (performance) pretendido ao nível do processo de inferência. A Figura 2 identifica os principais perfis associados ao OWL e a sua relação.

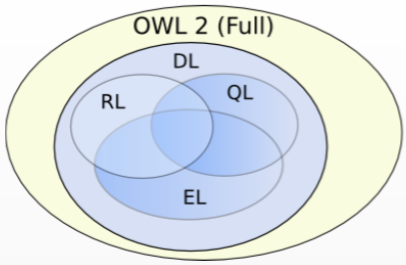
Figura 2: Principais perfis do OWL 2.
O perfil OWL-Full permite o uso de todos os elementos da linguagem sem qualquer tipo de restrição, nomeadamente sobre como e onde esses elementos podem ser utilizados. Esta liberdade permite, por exemplo, que um recurso (e.g. ex:Zebra) possa simultaneamente ser considerado uma instância (e.g. da classe ex:Animal) e uma classe (e.g. a classe representativa de todas as zebras). Consequentemente, este perfil não garante a existência de um algoritmo decidível. Neste contexto, diz-se que um algoritmo é decidível quando, independentemente do tempo despendido, este seja capaz de computar todas as inferências lógicas presentes numa ontologia (e.g. se um determinado recurso é ou não membro de uma dada classe).
O perfil OWL-DL também permite o uso de todos os elementos da linguagem, mas contrariamente ao OWL-Full, estabelece restrições sobre como e onde esses elementos podem ser utilizados de forma a garantir a existência de um algoritmo decidível. Por exemplo, este perfil impõe uma clara separação entre classes e indivíduos, não podendo o mesmo recurso ser as duas coisas em simultâneo.
Os perfis OWL-EL, OWL-QL e OWL-RL, para além das restrições impostas pelo OWL-DL, contemplam outras restrições, nomeadamente relacionadas com a especificação de quais elementos podem ser utilizados. Estas restrições visam tornar o perfil adequado para aplicações com um determinado conjunto de características. Neste sentido, o OWL‑EL é particularmente adequado para aplicações que manipulam ontologias com uma grande quantidade de classes e/ou de propriedades e cujas inferências ocorrem principalmente ao nível terminológico (TBox).
Por outro lado, o OWL-QL é particularmente adequado para aplicações que manipulam ontologias pequenas e cuja expressividade é reduzida, mas que possuem uma grande quantidade de indivíduos, tipicamente oriundos de uma base de dados relacional, e sobre os quais se pretende realizar inquéritos (queries). Este garante ainda que as respostas aos inquéritos são válidas (soundness), completas (completeness) e obtidas de forma eficiente.
Por último, o OWL-RL é particularmente adequado para aplicações que, por um lado, não pretendem sacrificar muito a expressividade da ontologia, mas por outro lado, pretendem que o processo de inferência seja escalável e eficiente. Para alcançar esse equilíbrio, o mesmo está talhado para que o processo de inferência se realize através de mecanismos baseados em regras.
Conclusões
Conclui-se esta visão geral sobre o OWL salientando algumas ideias-chave. Comparativamente a outras linguagens de esquema (e.g. o XSD, o UML, linguagem de definição de esquema do SQL), o OWL apresenta essencialmente três vantagens:
- É mais expressivo, na medida em que permite expressar ideias muito complexas e subtis sobre os dados. Por exemplo, contrariamente ao UML onde a hierarquia de classes é estabelecida de forma estática, em OWL essa hierarquia pode ser estabelecida de forma dinâmica, podendo até ser poli-hierárquica;
- É mais flexível, no sentido em que a especificação de um esquema em OWL corresponde à adição de novos triplos RDF e, portanto, é por natureza incremental. Logo, as aplicações assentes em OWL tendem a encarar alterações ao esquema de uma forma mais simples e natural do que as aplicações assentes nas linguagens de esquema mais tradicionais. Tipicamente, estas últimas assentam no paradigma mental de primeiro construir o esquema e depois usar esse esquema. Posteriormente, mesmo alterações básicas ao esquema são consideradas problemáticas pelo seu impacto e, consequentemente, são evitadas ou até mesmo nunca realizadas. Por exemplo, em OWL alterar um relacionamento de 1:1 para 1:n requer simplesmente, ao nível dos dados, a adição de um novo triplo. Por outro lado, realizar esta alteração num esquema de dados relacional requer a realização de várias operações como, por exemplo, a eliminação da coluna onde a relação 1:1 é armazenada, a criação de uma nova tabela para armazenar as relações 1:n, a criação de uma chave estrangeira, a eliminação e criação de novos índices, entre outras;
- É mais eficiente, na medida em que promove e suporta diversos tipos de inferência, o que permite, por exemplo, minimizar os dados que são explicitamente armazenados e a complexidade das consultas necessárias para recuperar esses mesmos dados. Neste particular, destaca-se a necessidade de, aquando da especificação de uma ontologia, se adotar o perfil mais adequado. Contudo, essa escolha depende essencialmente dos requisitos da aplicação onde se pretende utilizar a ontologia.
A descrição dos principais elementos da linguagem OWL e respetiva semântica será o foco do próximo artigo. Até lá, sugerimos aos nossos leitores que explorem algumas das várias aplicações que permitem construir ontologias em OWL. Uma lista (incompleta) dessas aplicações está disponível aqui.
Por hoje é tudo! Esperamos que tenha gostado e deixe a sua opinião.
Artigos relacionados
- Vamos Ligar e Partilhar? – Introdução às Ontologias
- Vamos Ligar e Partilhar? – Introdução ao SPARQL
- Vamos Ligar e Partilhar? – Introdução ao RDFS (Parte II)
- Vamos Ligar e Partilhar? – Introdução ao RDFS (Parte I)
- Vamos Ligar e Partilhar? – Introdução à Web Semântica
- Vamos Ligar e Partilhar? – Introdução ao RDF