Os sistemas distribuídos estão em todo o lugar, ou melhor, acessíveis a partir de qualquer lugar. Segundo Tanenbaum, um sistema distribuído é um conjunto de computadores independentes entre si (e até diferentes), ligados através de uma rede de dados, que se apresentam aos utilizadores como um sistema único e coerente.
Conheça a Framework Apache Flink que permite o processamento de grandes quantidades de dados.


O Apache Flink é a ferramenta de última geração do Big Data, conhecido como o 4G do Big Data. Esta framework:
- É uma true stream processing framework , ou seja, não corta a stream em micro-batches.
- O kernel ou core do Flink é um streaming runtime que também tem a capacidade de processamento distribuído, tolerância a falhas, etc.
- O Flink processa eventos a uma velocidade elevada constante com baixa latência.
- É uma framework de processamento de dados de larga escala com capacidade de processar dados gerados a grandes velocidades.
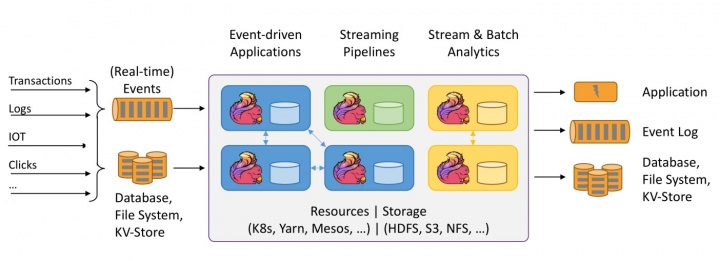

O Apache Flink é uma plataforma open source que pode responder aos seguintes requisitos de forma efetiva:
- Batch Processing
- Interactive processing
- Real-time stream processing
- Graph Processing
- Iterative Processing
- In-memory processing
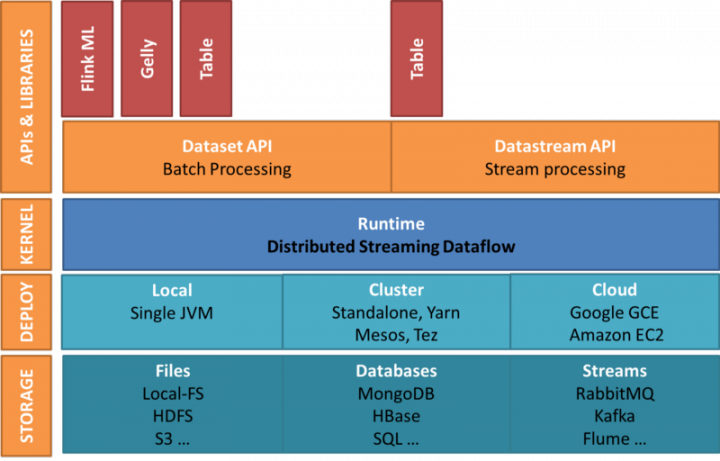
O Flink é uma alternativa ao MapReduce, usado, por exemplo, no Hadoop, e consegue processar dados 100 vezes mais rápido que o MapReduce. É independente do Hadoop, mas pode utilizar o HDFS para ler, escrever, guardar e processar dados. O Flink não tem um sistema de armazenamento de dados.

Num próximo artigo vamos mostrar como podem instalar o Apache Flink, num Multi-Node Cluster no Ubuntu 18.04 usando VirtualBox. Estejam atentos e se gostarem desta área da computação distribuída, partilhem ideias.