Há apagões que acontecem nos Datacenters que podem tornar a vida de milhões de pessoas num completo inferno. Sejam elas dependentes dos serviços afectados ou gestores de sites alojados em serviços onde podem acontecer “erros” humanos.
Para que sejam respeitadas todas as regras na construção de um Datacenter, evitando catástrofes e apagões que causam enormes prejuízos, deixamos algumas das mais elementares Regras para Datacenters.

Grande parte das pessoas pensa em fogos, terramotos ou inundações como um caso de desastre, ou pensam mesmo que desastres são coisas que não acontecem. Do ponto de vista organizacional e numa interacção directa com os Sistemas de Informação, qualquer evento que interfira, interrompa um serviço vital, corrompa dados ou até negue o acesso à informação pode ser interpretado como um desastre.

A construção de um Datacenter obriga a respeitar uma série de regras, mediante o objectivo para que está a ser criado, mas as forças da natureza são imprevisíveis em relação à dimensão dos estragos que possam fazer, por isso, quanto mais altos forem os padrões de exigência na sua elaboração mais protegidos estão os dados e serviços que são por si disponibilizados.
Segundo Sikich (2003), a habilidade para se responder de forma eficaz na gestão de interrupções de serviço de uma forma atempada é agora um factor decisivo na sobrevivência de uma organização. A decisão de se implementar uma solução de disaster recovery [1] deve assim depender do balanço entre o risco de ocorrência de determinados tipo de desastres e a vulnerabilidade do negócio na eventualidade da sua ocorrência.
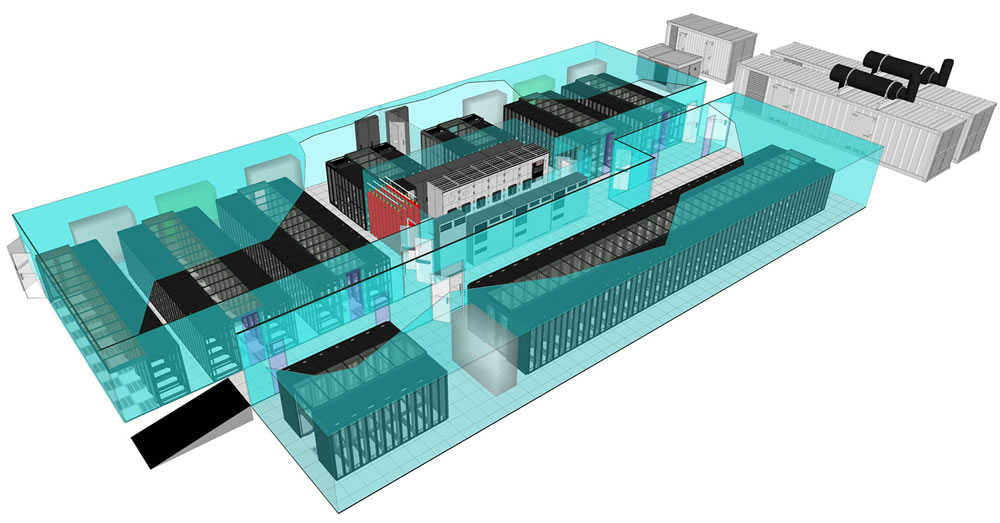
Neste sentido este artigo apresenta várias soluções e características que os Datacenter devem possuir para cumprir com as exigências e salvaguardar tecnicamente o seu funcionamento.
1 Datacenter
A norma Telecommunications Infrastruture Standard for Datacenters (TIA) 942 é a principal orientação na construção de um Datacenter. É nesta norma que estão todas a regras para a construção de um Datacenter, regras a cumprir, topologias e todo o tipo de requisitos que asseguram o bom funcionamento do mesmo.
2.1 Estrutura e Topologia
Existem uma série de elementos a tomar em conta para um projecto de construção de um Datacenter, todos os sistemas terão uma relação directa no futuro funcionamento do mesmo. Assim temos que considerar como principais pontos da estrutura tudo o que esteja relacionado com:
- Telecomunicações
- Tipos de cabos a utilizar
- Zona de passagem dos cabos
- Ativos de rede
- Arquitetura
- Gestão
- Segurança
- Manutenção
- Ambiente
- Infraestrutura Elétrica
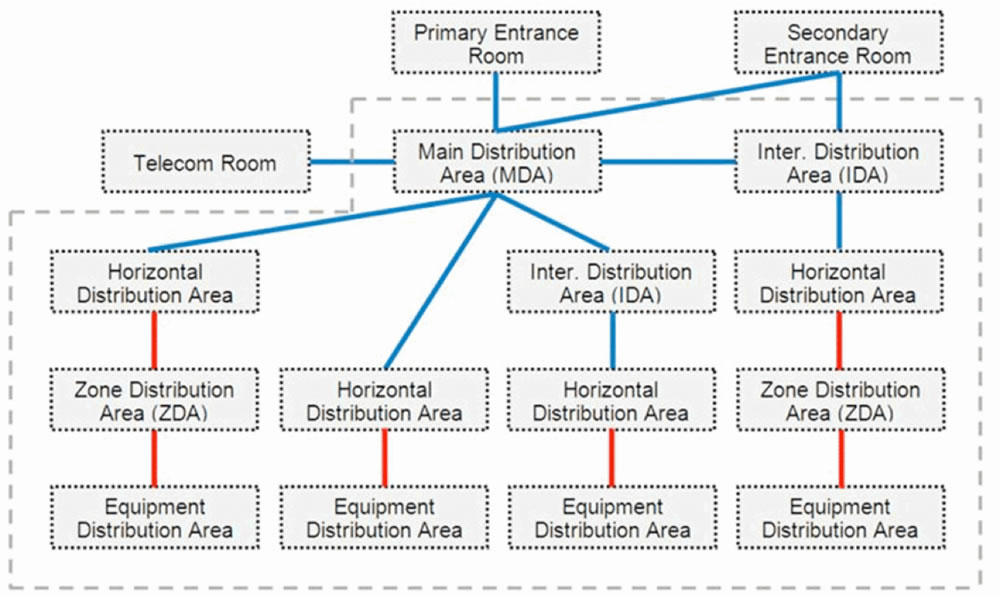
Está também definido na norma TIA 942 a topologia (apresentada na figura 1) que um Datacenter deve ter, nomeadamente:
- ER – Entrance Room – Espaço de interconexão entre a cablagem estruturada dos operadores de telecomunicações e o Datacenter;
- MDA – Main Distribuition Area – É uma área critica, pois é nesta zona que e feita a distribuição dos cabos estruturados pelo Datacenter;
- HDA – Horizontal Distribuition Area – Interliga vários equipamentos principais com equipamentos secundários;
- ZDA – Zone Distribuition Area – Normalmente localizada sob o piso é um ponto de interligação entre o HDA e o EDA;
- EDA – Equipment Distribuition Area – Espaço destinado aos equipamentos de comunicações de dados ou voz e equipamentos terminais (Servidores e Armazenamento).
2.2 Classificação
A norma TIA-942 é bem explícita quanto aos requisitos que um Datacenter deve ter. Conforme o tipo de negócio e as suas características é lhe atribuído um nível de criticidade (figura 2). Consoante as regras forem cumpridas é realizada a sua classificação.
![Figura 2 – Níveis de Criticidade de um Datacenter [3]](https://pplware.sapo.pt/wp-content/uploads/2015/02/imagem_datacenter_disaster04.jpg)
Existem 4 Tier, que correspondem a cada nível e os seus requisitos são:
- Tier I – Básico. É o nível mais baixo aceite pela norma TIA 942 que cumpre os requisitos mínimos de um nível de criticidade 1, são também chamados os Datacenters básicos. Toda a distribuição de comunicações interna é feita por um único caminho, não existe qualquer redundância lógica nem física. Ao nível elétrico existe um mínimo ou nenhum suporte adicional, logo qualquer quebra de energia poderá provocar a sua interrupção de funcionamento. No entanto é exigido que tenha ar condicionado de modo a manter uma temperatura estável e recomendada à dimensão da sala EDA. A sua implementação demora à volta de 3 meses. Os principais motivos de quebra de serviço a este nível são: (1) Falha nos routers; (2) Falha nas comunicações; (3) Falha no fornecimento de energia eléctrica e (4) Qualquer falha na cablagem na ligação entre as zonas
Permite-se neste tipo de situação um downtime [4] de até 28.8 horas anuais.
- Tier II – Redundante. Neste nível é já necessário que computadores e as unidades de armazenamento possuam fonte de alimentação redundante. As ligações entre zonas já terão de ser de fibra ou cabo entrançado redundante. O fornecimento de energia elétrica deve estar assegurado por UPS assim como a existência de um gerador auxiliar. O Ar Condicionado deve estar preparado para funcionar em contínuo 24h por dia. Não é exigido redundância no fornecimento externo de energia. A sua implementação demora entre 3 a 6 meses.
O principal motivo de falha a este nível tem a ver com uma falha no Ar Condicionado.
Neste caso permite-se um downtime de até 22 horas anuais.
- Tier III – Auto Sustentado. Um Datacenter para poder ser classificado neste nível, deve haver pelo menos dois fornecedores de telecomunicações, com circuitos independentes, evitando assim um ponto de falha. Deve haver em todas as salas sistema de proteção conta incêndios e sistemas de fornecimento de energia e ar condicionado distintos. Todos os ativos críticos deverão possuir um sistema de redundância pronto a ser acionado. Deve ser possível alterar a disposição da sala sem interrupção de serviços. O sistema de HVAC [5] deve ser do tipo N+1 onde para além de redundância haverá um spare [6] que por automatismo entrará em funcionamento em caso de falha de um dos principais, fazendo com que todo o ambiente dentro do Datacenter se mantenha com as temperaturas desejadas, mesmo numa situação de manutenção do sistema de arrefecimento. A sua implementação demora entre 6 meses a um ano.
O ponto fraco neste tipo de instalação está no caso de haver alguma interrupção entre o MDA e o HDA.
Permite-se o downtime anual de 1,6h anuais.
- Tier IV – Tolerante a falhas. Para se obter este tipo de classificação, para além de cumprir todos os requisitos das categorias anteriores, deverá também ter fornecimento de dois provedores distintos de energia elétrica com a alimentação proveniente de duas subestações diferentes para fins de redundância. Toda a cablagem deve ser redundante e possuir canais próprios para a sua passagem completamente independentes e em tubagem resistente. Todo o sistema de ativos deve ser redundante e possuir sistemas automáticos de entrada em funcionamento. O sistema de HVAC deverá possuir fontes de alimentação duplas com fornecimentos distintos. A implementação de um sistema com estes requisitos poderá demorar entre um ano a dezoito meses.
Os problemas aqui poderão aparecer caso não se implemente um MDA secundário ou então não se implemente um HDA secundário.
Para este caso permite-se um downtime de 0.4 horas anuais.
Convém mencionar que as exigências são cumulativas, ou seja, para um determinado Datacenter ser classificado num determinado Tier tem que cumprir os requisitos desse Tier e todas as dos Tier anteriores.
Este tipo de exigências tem como foco principal a continuidade de fornecimento de serviços para que um Datacenter foi construído. Uma das entidades que faz a certificação aos datacenters é a UptimeInstitute [7].
3 Gestão da Continuidade
Segundo Syed (2004), o planeamento para a gestão da continuidade pode ser considerado uma disciplina que prepara a organização para manter a continuidade dos seus serviços durante a ocorrência de um desastre, através da implementação de um plano de contingência.
A interrupção da continuidade numa organização vai representar custos, o cálculo desses custos será sempre baseado no objecto da própria organização. Empresas do mesmo ramo mas com objectivos diferentes podem ter custos diferentes, quando da interrupção dos serviços de Tecnologias de Informação (TI).
Os valores que constam na tabela 1 apresentam alguma antiguidade, mas no entanto facilmente se pode comprovar que existem custos muito altos por cada hora de interrupção de disponibilização de serviços. No entanto existem na nossa realidade organizações públicas e privadas que descuram o investimento em soluções de gestão de continuidade, pois representam investimentos e processos dispendiosos onde o retorno do investimento (ROI) é difícil de justificar.
O investimento na gestão de continuidade teria de ser feito em diferentes áreas como Recursos Humanos, Datacenter, Servidores, Software, Redes de Comunicações, etc. onde nem sempre se vê diretamente o resultado da sua eficiência.
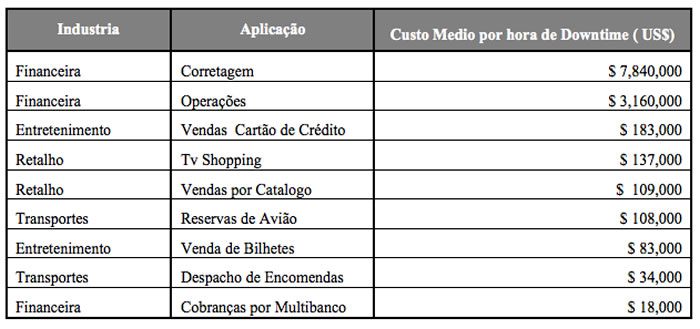
Por outro lado uma falha nos sistemas afecta a organização de imediato provocando uma perda de imagem, perda de clientes e até perda de credibilidade nos mercados, que por sua vez ira provocar a medio prazo quebra nas vendas, quebra na cobrança e custos financeiros.
Para muitos existe a associação de continuidade com segurança. Não é de facto a mesma coisa embora possa haver algum tipo de relacionamento. A existência de backups da informação só por si confere segurança e não continuidade, pois o ato reposição de seguranças pode provocar interrupção de serviços. No entanto a existência de backups confere credibilidade à organização, a realização de backups também esta sujeita a regras.
4 Arquiteturas tolerantes a falhas
Com a necessidade de reforçar a continuidade dos serviços disponibilizados pelos Datacenter e mesmo obedecendo às regras impostas para que obtenham uma determinada categoria, podem existir problemas internos e ainda situações de catástrofe que pela força da natureza poderão implicar estragos não previstos. Trata-se de evitar o impensável.
Entra-se então no campo da alta disponibilidade, ou seja, disponibilidade a um outro nível, com intervenção de recursos situados num ou mais Datacenter dispersos geograficamente. Para Weygant (2001), a alta disponibilidade caracteriza um Sistema de Informação que é desenhado de forma a evitar a perda de serviços, reduzir e gerir falhas e ao mesmo tempo minimizar a indisponibilidade aplicacional. Existem dois tipos de downtime, os que são geridos de uma forma controlada, como é o caso de backups, upgrade de sistemas, revisões e atualizações, e os que não são planeados como acontecimentos imprevistos que provocam a negação de acesso temporária à informação.
Para resolver este tipo de problemas usam-se vários tipos arquiteturas:
- Arquitetura Alta Disponibilidade
- Cluster Local
- Arquitetura Distaster Tolerant
- Campus Cluster
- Metropolitan Cluster
- Regional Cluster
- Continental Cluster
4.1 Arquitetura Alta Disponibilidade
Quando nos referimos a um Cluster Local estamo-nos a referir a alta disponibilidade local, ou seja, estamos a assegurar a disponibilização de serviços mas no caso de catástrofe não conseguimos assegurar a continuidade, no entanto conseguimos atingir uma boa performance face à distribuição das aplicações pelos diversos clusters de servidores. Salvaguardamos para este caso a paragem de uma das aplicações que será automaticamente transportada para um outro servidor. No caso da figura 3 existe uma falha na aplicação A no Sistema 1.
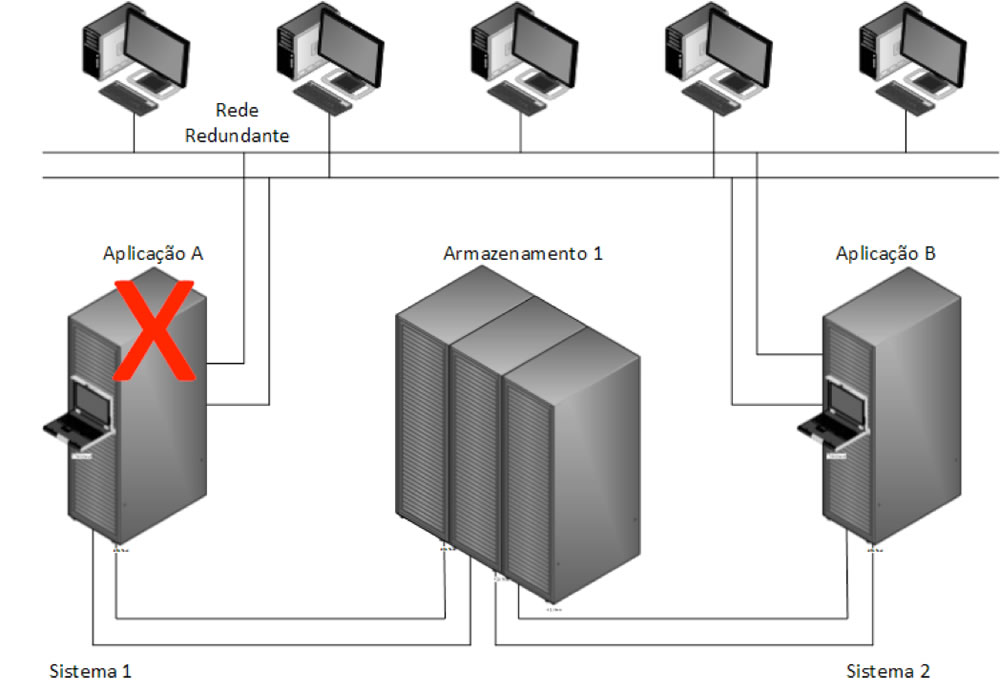
Como se pode verificar existe redundância de rede e também de servidores, existem duas aplicações a serem disponibilizadas pelo sistema, uma em cada conjunto de servidores, o sistema de Cluster ao detetar uma quebra de serviço pelo sistema 1 vai automaticamente passar a disponibilidade da aplicação para o sistema 2 ficando o sistema 2 a disponibilizar a aplicação A e B enquanto se precede à intervenção para resolver o problema do sistema 1.
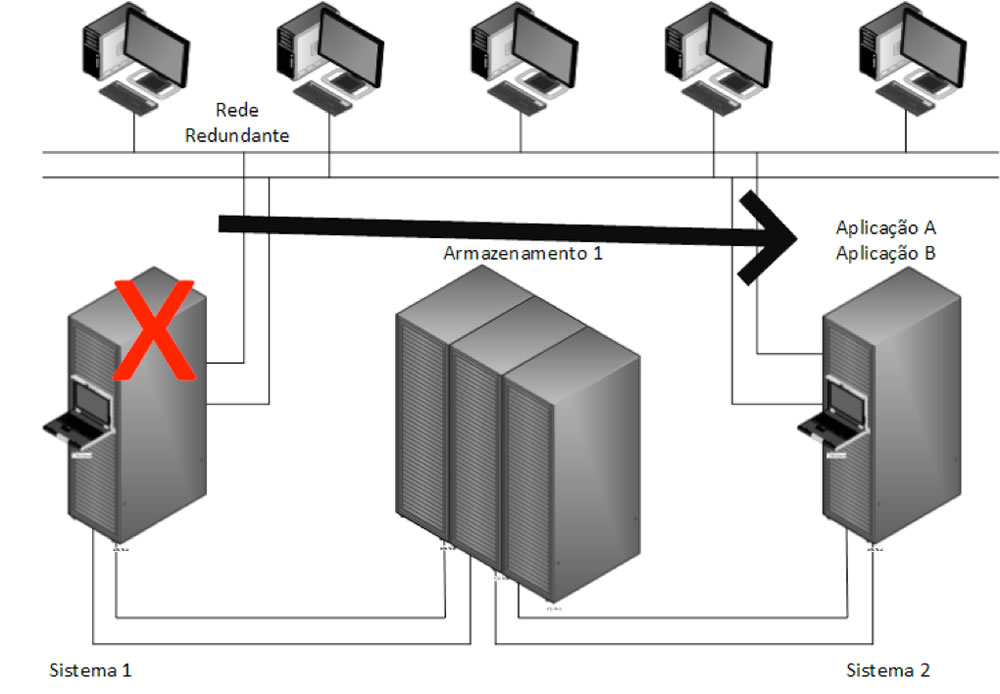
Para algumas organizações este tipo de proteção poderá não ser suficiente porque não é um Cluster Disaster Tolerant.
4.2 Arquitectura Disaster Tolerant
Quando se fala em Cluster Campus, Metropolitan, Regional e Continental, as diferenças principais estão no modo como os diferentes Datacenter se situam geograficamente e como é feita a ligação entre eles.
No caso de um Cluster Campus referimo-nos a uma área com edifícios separados por pouca distância e com ligações de alta velocidade entre eles que possam garantir um acesso a todos os nós do Cluster com as premissas exigidas de um ambiente Disaster Tolerant. No caso do Metropolitan já nos estamos as referir a Datacenter dentro de uma cidade mas em locais bem distintos e distanciados, já no caso de um Cluster Regional falamos de cidades ou regiões adjacentes.
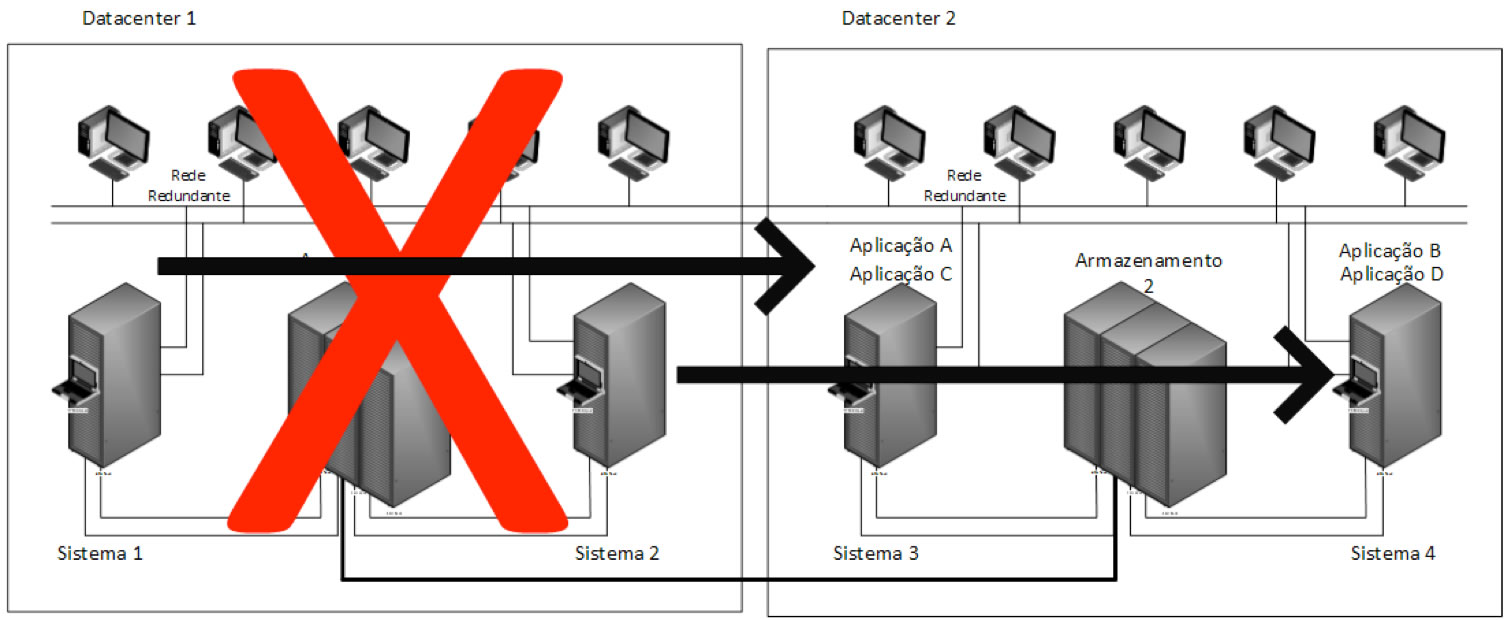
Num Cluster Continental os principais sistemas estão separados por distâncias superiores a 300 Km, logo implica a contratação de telecomunicações de alto rendimento e isso acarreta custos muito elevados para a sua implementação. Na Figura 5 podemos ver um exemplo de uma arquitetura com dois Datacenter com as condições de Disaster Tolerant.

Numa situação de Disaster Recovery num dos Datacenter em questão e por automatismo as aplicações em causa irão transferir a sua disponibilidade de um Datacenter para o outro, mantendo assim todos os clientes com o acesso pretendido.
Neste tipo de solução há um grande sincronismo entre os dois conjuntos de armazenamento, funcionando em modo espelho, ou seja, todo o conjunto de informação que está num reflete-se em tempo real no outro.
Quando a comunicação é interrompida por falha num dos lados é feita a mudança de serviços (figura 6), quando a situação for reposta primeiro terá de haver uma reposição de tudo o que aconteceu anteriormente até que se possa ter um sincronismo total e assim se ficar na situação de ideal, com os dois Datacenter a funcionar e a carga balanceada entre eles.
Foi feita uma abordagem em termos lógicos da estruturas a utilizar, no entanto convém também não esquecer que neste tipo de processo existem os recursos humanos, que são peça fundamental na avaliação e programação das tarefas objectivas do Datacenter. Por outro lado também a qualidade do material pode ser de importância vital para um bom funcionamento da toda a estrutura.
5 Conclusão
A Gestão da continuidade não se limita à instalação de um bom software de gestão para ambientes de alta disponibilidade. A construção de um Datacenter obriga a cumprir normas, normas estas que lhe irão dar uma determinada categoria, no entanto mesmo ao mais alto nível estamos sempre sujeitos ao impensável, ao desastre natural que vai impedir o seu funcionamento e provocar uma falha na continuidade.

Utilizando soluções de Disaster Tolerant podemos ir mais longe. Dependendo da área a abranger pelos serviços que estamos a disponibilizar e usando as diversas arquiteturas existentes conseguimos salvaguardar a imagem da organização no que diz aspecto à sua informação.
O retorno do investimento nem sempre é visível, pelo que tomar uma decisão no âmbito da continuidade de serviços implica uma visão correta do quão importante é manter disponível a informação.
Referências
Referências
- Sikich, G.W., “Integrated Business Continuity : Maintaining Resileince in Uncertain Times”, PennWell Books, 2003.
- Syed, A. Ph.D. & Syed, A.,”Business Continuity Planning Methodology”, Sentryx , 2003.
- Weygant, P.S.,”Clusters for High Availability:A Primer of HP Solutions”, Prentice Hall, 2001.
- Serrano, A. e Jardim, N.,” Disaster Recovery – Um Paradigma na Gestao da Continuidade” , FCA Editora, 2007.
- Cisco, “Data Center High Availability Clusters Design Guide”, ( acedido em http://www.cisco.com/en/US/docs/solutions/Enterprise/Data_Center/HA_Clusters/HAGeoC_3.html)
- HP, “Arbitration in Disaster-Tolerant Clusters”, ( acedido em http://docstore.mik.ua/manuals/hp-ux/en/B3936-90078/ch01s08.html)
- APC Media , “Guidelines for Specifying Data Center Criticality / Tier Levels”, ( acedido em http://www.apcmedia.com/salestools/VAVR-6PHPBU/VAVR-6PHPBU_R1_EN.pdf )
[1] Disaster recovery – Reposição em caso de desastre
[2] Fonte: Telecommunications Infrastruture Standard for Data Centers (2005)
[3] Fonte : APC ( 2010 ) Guidelines for Specifying Data Center Criticality / Tier Levels
[4] Downtime – tempo de inoperacionalidade
[5] HVAC – Aquecimento, Ventilação e Ar Condicionado
[6] Spare – suplente
[7] http://uptimeinstitute.com/TierCertification/
[8] Fonte: Contingency Planning Research (2002)
Elaborado por João Maria Sesifredo Pimentel