O Apache Hadoop é uma framework desenvolvida em Java, para computação distribuída, usada para processamento de grandes quantidades de informação. O Hadoop é, por exemplo, usado por grandes plataformas mundiais como é o caso do Facebook.
Hoje vamos ensinar como podem instalar o Apache Hadoop no Ubuntu 18.04.


Para melhor entender o que vai ser feito neste tutorial, deve saber que o Hadoop está dividido em duas partes essenciais:
Hadoop Distributed File System (HDFS)
- Sistema de ficheiros distribuído que armazena dados em máquinas dentro do cluster.
Hadoop MapReduce
- Modelo de programação para processamento em larga escala.
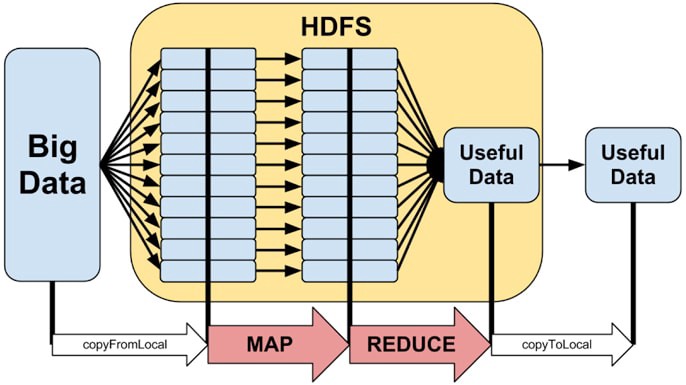
A figura seguinte representa o modelo de programação MapReduce

Pré-requisitos:
- Ubuntu 18.04 (Máquina virtualizada no VirtualBox ou outra plataforma)
- Java instalado
- Apache Hadoop
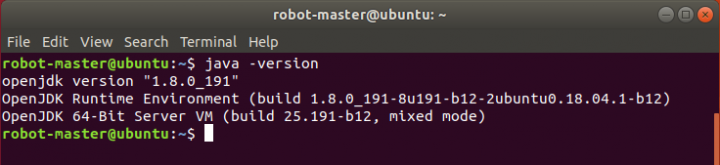
Para verificar se tem o java instalado na sua máquina, deve executar o seguinte comando:
user@ubuntu:~$ java -version

Caso não tenha o java instalado, basta executar os seguintes comandos:
user@ubuntu:~$ sudo apt-get install default-jre
user@ubuntu:~$ sudo apt-get install default-jdk
Passo 1) Configuração do utilizador Hadoop
Depois do java instalado, o primeiro passo é criar um utilizador Hadoop no sistema para acesso ao HDFS e MapReduce.
Para evitar problemas de segurança, é recomendável configurar um novo grupo de utilizadores do Hadoop.
user@ubuntu:~$ sudo addgroup hadoop


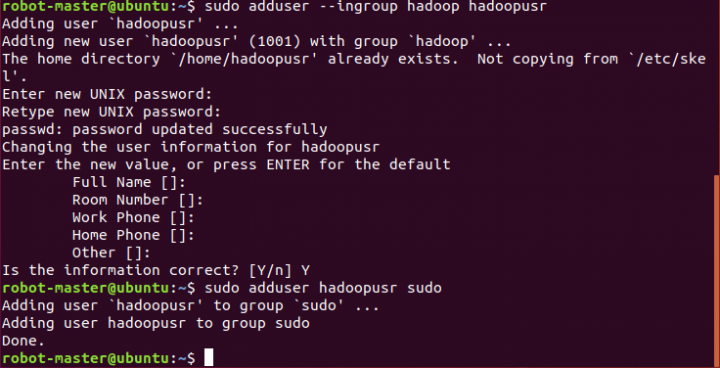
Adicionar um utilizador Hadoop de nome hadoopusr
user@ubuntu:~$ sudo addusr -–ingroup hadoop hadoopusr
user@ubuntu:~$ sudo adduser hadoopusr sudo

Passo 2) Instalação e configuração do OpenSSH
De seguida vamos proceder à instalação e configuração do SSH.
Para instalar o OpenSSH Server, basta executar o seguinte comando:
user@ubuntu:~$ sudo apt-get install openssh-server


O Hadoop usa o SSH para aceder aos nós. Neste caso, como estamos a fazer uma configuração para um single-node, necessitamos de configurar o SSH para aceder ao localhost.
Vamos entrar com o utilizador hadoopusr
user@ubuntu:~$ su — hadoopusr


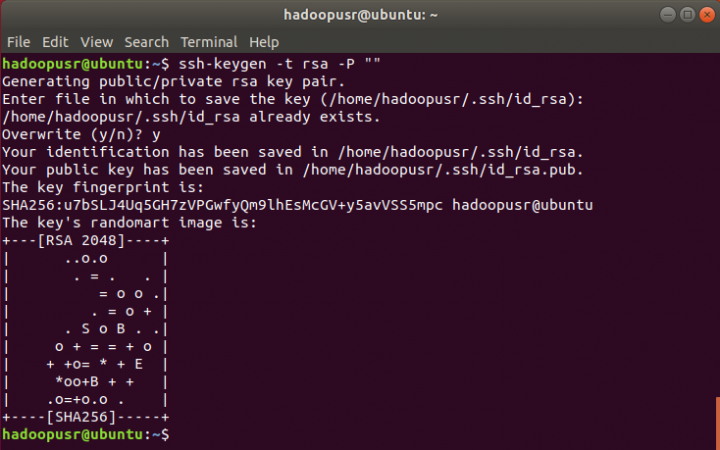
O próximo passo é gerar uma chave publica SSH para o hadoopusr
hadoopusr@ubuntu:~$ ssh-keygen -t rsa -P “”

De seguida, vamos adicionar a chave gerada anteriormente para a lista de authorized_keys. Para isso, basta executar o seguinte comando:
hadoopusr@ubuntu:~$ cat $HOME/ .ssh/id_rsa.pub >> $HOME/ .ssh/authorized_keys


Para verificar se o SSH está a funcionar, deve utilizar o seguinte comando:
hadoopusr@ubuntu:~$ ssh localhost

No fim, deve executar o comando exit para terminar a ligação.
Passo 3) Instalação e configuração do Hadoop
Vamos agora proceder ao download do Hadoop 2.9.1.
A ficheiro ficará no ambiente de trabalho. Para isso, basta executar o seguinte comando:
hadoopusr@ubuntu:~$ sudo wget -P /home/user/Desktop http://mirrors.sonic.net/apache/hadoop/common/hadoop-2.9.1/hadoop-2.9.1.tar.gz


Mudamos o diretório para o Desktop para proceder à descompactação da pasta do Hadoop
hadoopusr@ubuntu:~$ cd /home/user/Desktop
hadoopusr@ubuntu:~$ sudo tar xvzf hadoop-2.9.1.tar.gz


Feita a descompactação, vamos mover a pasta para o diretório /usr/local/hadoop
hadoopusr@ubuntu:~$ sudo mv hadoop-2.9.1 /usr/local/hadoop


Vamos atribuir a propriedade da pasta ‘hadoop’ ao utilizador hadoopusr
hadoopusr@ubuntu:~$ sudo chown -R hadoopusr /usr/local


Procedamos agora à configuração de diversos ficheiros. A configuração do Apache Hadoop deverá começar pela definição das seguintes variáveis de ambiente que deverão estar no ficheiro ~/.bashrc.
hadoopusr@ubuntu:~$ sudo gedit ~/.bashrc
Depois de executar o comando anterior, deve copiar as seguintes configurações para o final do ficheiro
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS=""
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar
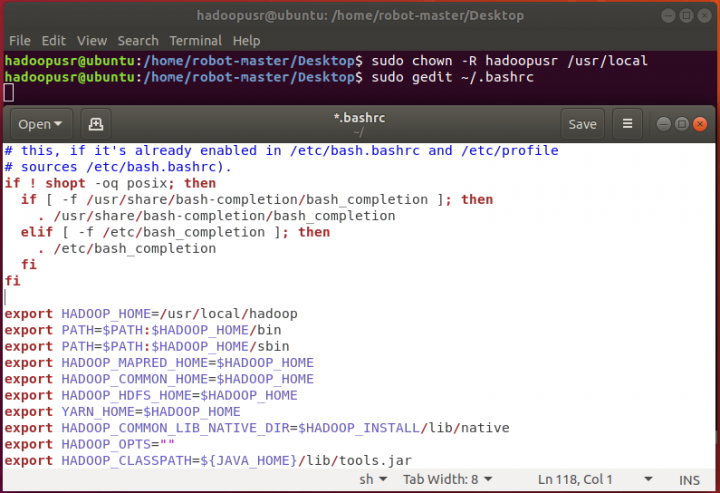

Clique em ‘Save’ e depois, para que a configuração seguinte tenha efeito na sessão corrente, basta que use o comando.
hadoopusr@ubuntu:~$ source ~/.bashrc
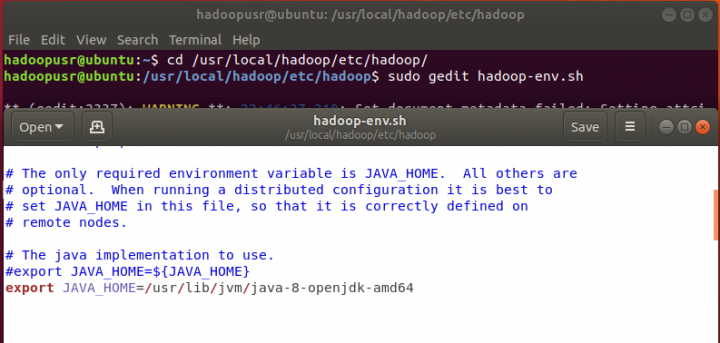
Vamos agora editar o ficheiro hadoop-env.sh e definir a variável de ambiente JAVA_HOME.
hadoopusr@ubuntu:~$ cd /usr/local/hadoop/etc/hadoop/
hadoopusr@ubuntu:~$ sudo gedit hadoop-env.sh
Basta adicionar a seguinte linha ao ficheiro, colocando a que já lá está em comentário, utilizando um ‘#’ antes da frase.
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
Nota: Dependendo da versão do java que tem instalado na máquina, deve alterar o último nome do caminho (java-8-openjdk-amd64). Tipicamente, só necessita de alterar o número da versão do java.

O Apache Hadoop tem muitos ficheiros de configuração. Estes ficheiros permitem diversas configurações, de acordo com as necessidades de cada utilizador. Como vamos configurar um simples nó de um cluster, basta configurar os seguintes ficheiros:
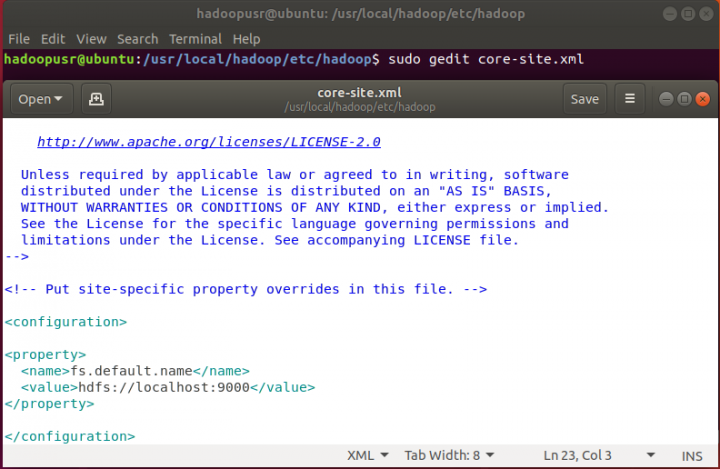
1 – core-site.xml
hadoopusr@ubuntu:~$ sudo gedit core-site.xml
Acrescentar dentro da tag a seguinte propriedade:
fs.default.name
hdfs://localhost:9000

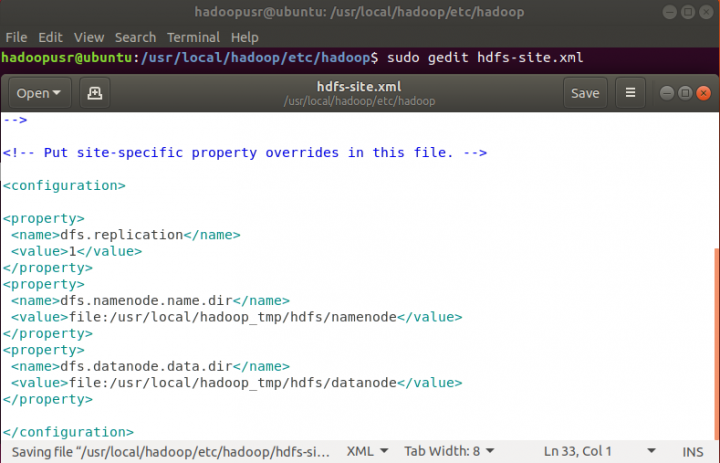
2. hdfs-site.xml
hadoopusr@ubuntu:~$ sudo gedit hdfs-site.xml
Acrescentar dentro da tag as seguintes propriedades:
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop_tmp/hdfs/namenode
dfs.datanode.data.dir
file:/usr/local/hadoop_tmp/hdfs/datanode

3. yarn-site.xml
hadoopusr@ubuntu:~$ sudo gedit yarn-site.xml
Acrescentar dentro da tag as seguintes propriedades:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler


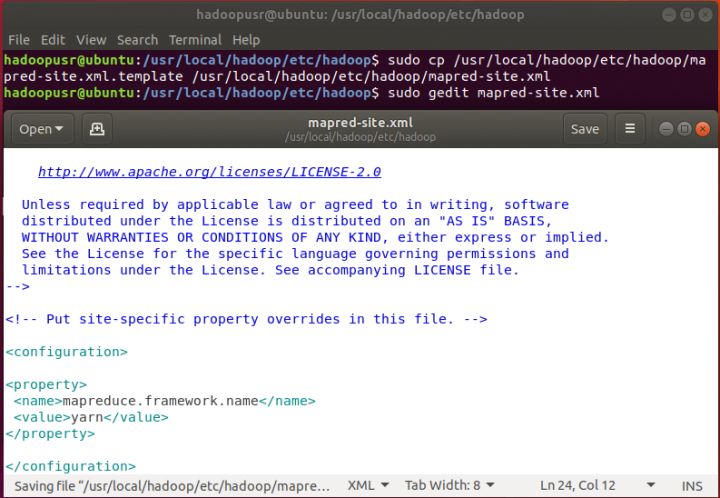
4. mapred-site.xml
Uma vez que o nome do ficheiro, por defeito, é mapred-site.xml.template, terá de renomear o ficheiro para mapred-site.xml, utilizando o seguinte comando:
hadoopusr@ubuntu:~$ sudo cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml


E só depois é que passa à edição…
hadoopusr@ubuntu:~$ sudo gedit mapred-site.xml
Acrescentar dentro da tag as seguintes propriedades:
mapreduce.framework.name
yarn
</property

Vamos agora criar diretórios para o namenode e o datanode, para isso, basta executar os seguintes comandos:
hadoopusr@ubuntu:~$ sudo mkdir -p /usr/local/hadoop_space/hdfs/namenode
hadoopusr@ubuntu:~$ sudo mkdir -p /usr/local/hadoop_space/hdfs/datanode

Feitas as configurações nos ficheiros anteriores, vamos formatar o namenode usando o seguinte comando, atribuindo primeiro a propriedade da pasta ‘hadoop_space’ ao utilizador hadoopusr.
hadoopusr@ubuntu:~$ sudo chown -R hadoopusr /usr/local/hadoop_space
hadoopusr@ubuntu:~$ cd
hadoopusr@ubuntu:~$ hdfs namenode -format


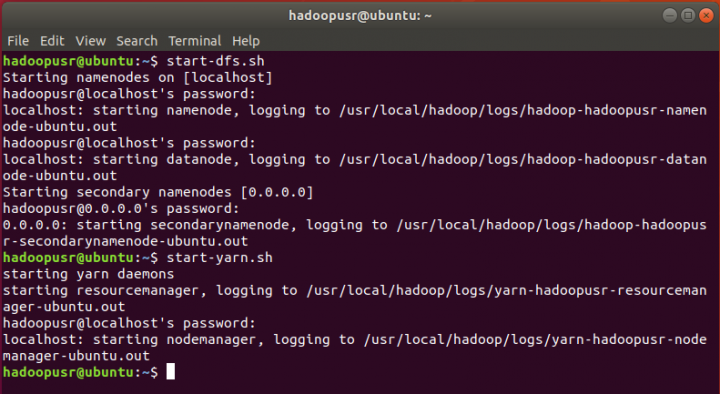
Por fim, vamos iniciar todos os serviços associados ao hadoop. Para tal, basta executar os seguintes comandos:
hadoopusr@ubuntu:~$ start-dfs.sh
hadoopusr@ubuntu:~$ start-yarn.sh

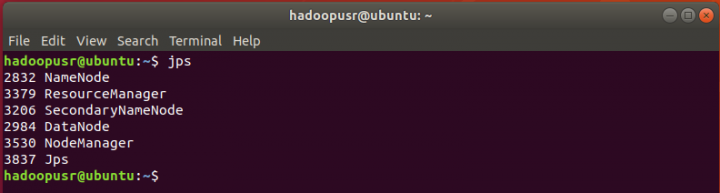
Para verificar se todos os serviços iniciaram corretamente, deve executar o comando:
hadoopusr@ubuntu:~$ jps

Para aceder à interface de gestão do Apache Hadoop basta abrir o browser e inserir o seguinte URL: http://localhost:8088


Se conseguiu chegar até aqui, pode vangloriar-se para todos os seus amigos de que conseguiu instalar o Apache Hadoop com sucesso!